1 常见查询
1.1 语法顺序、执行顺序
01.大小写
SQL不区分大小写
Linux区分大小写
02.MySQL的语法顺序
SELECT
FROM
JOIN
ON
WHERE
GROUP BY
HAVING
UNION
ORDER BY
LIMIT
03.SQL执行顺序
(8) SELECT
(9) DISTINCT
(11) <Top Num> <select list>
(1) FROM [left_table]
(3) <join_type> JOIN <right_table>
(2) ON <join condition>
(4) WHERE <where condition>
(5) GROUP BY <group_by_list>
(6) WITH <CUBE | RollUP>
(7) HAVING <having_condition>
(10) ORDER BY <order by_list> ASC升序 | DESC降序
f o j w g w h s d o top
from on join where groupby with having select distinct orderby top
from 2张表生成一个笛卡尔积 生成“虚表1”
on 2张表进行一个关联匹配 生成“虚表2”
join 左/右关联,根据左/右表添加一个外部行 生成“虚表3”
where 行筛选 生成“虚表4”
groupby 列分组 生成“虚表5”
with 所选列中值的组合聚合 生成“虚表6”
having 符合分组条件进行筛选 生成“虚表7”
select 选择列 生成“虚表8”
distinct 删除重复数据行 生成“虚表9”
orderby 排序生成游标 生成“虚表10”
<Top 数字> 选择前几条 生成“虚表11”
<select list> 将执行list结果返回
1.2 整体分类
00.为什么要使用数据库
数据保存在内存
优点: 存取速度快
缺点: 数据不能永久保存
数据保存在文件
优点: 数据永久保存
缺点:1)速度比内存操作慢,频繁的IO操作。2)查询数据不方便
数据保存在数据库
1)数据永久保存
2)使用SQL语句,查询方便效率高。
3)管理数据方便
00.什么是SQL?
结构化查询语言(Structured Query Language)简称SQL,是一种数据库查询语言。
作用:用于存取数据、查询、更新和管理关系数据库系统。
00.分类
DQL:数据查询语言 select
DML:数据操作语言 insert delete update --> 可以回退(可以进行事务操作)
DDL:数据定义语言 create drop truncate alter --> 不可以回退(可以进行事务操作)
DCL:数据控制语言 grant revoke commit rollback
DQL:数据查询语言 select 查询操作,以select关键字。各种简单查询,连接查询等都属于DQL
DML:数据操作语言 insert delete update DQL与DML共同构建了常用的增删改查操作,而查询是较为特殊的一种被划分到DQL中
DDL:数据定义语言 create drop truncate alter 对逻辑结构等有操作的,其中包括表结构,视图和索引
DCL:数据控制语言 grant revoke commit rollback 对数据库安全性完整性等有操作的,可以简单的理解为权限控制等
00.常见
范围查询 between
模糊查询 like 数字、字母、日期
分组查询+多行函数/聚合函数/数字函数/组函数 group by
排序查询 order by
-----------------------------------------------------------------------------------------------------
单行函数 字符函数、数值函数、日期函数、转换函数、通用函数
多行函数/聚合函数/数字函数/组函数 从一组记录中返回一条记录,可出现在select列表、ORDER BY和HAVING子句中
01.子句
TOP/LIMIT/ROWNUM
SELECT子句
DISTINCT子句
WHERE子句
WHERE子句AND、OR
GROUP BY子句
GROUP BY 聚合函数/数字函数
HAVING子句
ORDER BY子句
02.集合运算
UNION(并集) 返回各个查询的所有记录,不包括重复记录
UNION ALL(并集) 返回各个查询的所有记录,包括重复记录
INTERSECT(交集) 返回两个查询共有的记录
MINUS(差集) 返回包含在第一个查询中,但不包含在第二个查询中的记录
03.多表连接
1.交叉连接(笛卡儿积) CROSS JOIN
2.内连接 INNER JOIN
等值连接:ON A.id=B.id
不等值连接:ON A.id > B.id
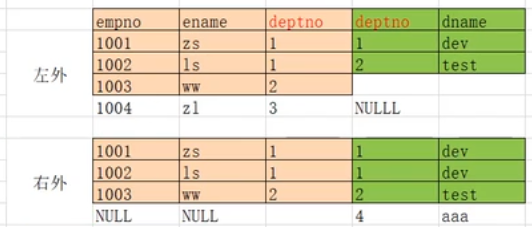
3.外连接
左外连接 LEFT OUTER JOIN, 以左表为主,先查询出左表,按照ON后的关联条件匹配右表,没有匹配到的用NULL填充,简写成LEFT JOIN
右外连接 RIGHT OUTER JOIN, 以右表为主,先查询出右表,按照ON后的关联条件匹配左表,没有匹配到的用NULL填充,简写成RIGHT JOIN
4.全外连接=左外连接+右外连接+去重 FULL JOIN
MySQL不支持全连接,可以使用LEFT JOIN 和UNION和RIGHT JOIN联合使用
04.mysql中in和exists区别
mysql中的in语句是把外表和内表作hash连接,而exists语句是对外表作loop循环,每次loop循环再对内表进行查询。一直大家都认为exists比in语句的效率要高,这种说法其实是不准确的。这个是要区分环境的。
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in。
not in 和not exists:如果查询语句使用了not in,那么内外表都进行全表扫描,没有用到索引;而not extsts的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
1.3 AS用法
01.别名的作用
SQL 别名用于为表或表中的列提供临时名称。
SQL 别名通常用于使列名更具可读性。
SQL 一个别名只存在于查询期间。
02.使用别名的场景
查询涉及多个表
用于查询函数
需要把两个或更多的列放在一起
列名长或可读性差
03.列的别名语法
SELECT column_name AS alias_name
FROM table_name;
04.表的别名语法
SELECT column_name(s)
FROM table_name AS alias_name;
1.4 NULL用法
01.如果是null,必须用is ,或is not
SQL> select * from emp where mgr is null;
EMPNO ENAME JOB MGR HIREDATE
7839 KING PRESIDENT 17-11月-81
02.null:任何数字和null结算,结果为null
SQL> select empno, ename, sal, comm, sal*12+comm 年薪 from emp where empno>=7400;
EMPNO ENAME SAL COMM 年薪
---------- -------------------- ---------- ---------- ----------
7654 MARTIN 1250 1400 16400
7698 BLAKE 2850
7839 KING 5000
7844 TURNER 1500 0 18000
03.需要对null进行处理:null->0
-- nvl:if
nvl(comm,0 )
SQL> select ename,comm from emp; SQL> select ename,nvl(comm,0) from emp;
ENAME COMM ENAME NVL(COMM,0)
-------------------- ---------- -------------------- -----------
SMITH SMITH 0
ALLEN 300 ALLEN 300
WARD 500 WARD 500
JONES JONES 0
MARTIN 1400 MARTIN 1400
BLAKE BLAKE 0
CLARK CLARK 0
SCOTT SCOTT 0
KING KING 0
-- nvl2:if...else
nvl2(comm,comm,0)
if(comm==null)
return 0
else
return comm
select ename,comm,nvl(comm,0),nvl2(comm,comm,0) from emp
ENAME COMM NVL(COMM,0) NVL2(COMM,COMM,0)
-------------------- ---------- ----------- -----------------
SMITH 0 0
ALLEN 300 300 300
WARD 500 500 500
JONES 0 0
MARTIN 1400 1400 1400
BLAKE 0 0
CLARK 0 0
SCOTT 0 0
KING 0 0
04.not in包含null值
select * from user where uid not in (a,b,c,null);
这个sql不回返回任何结果。要避免not in的list中出现null的情况。
---------------------------------------------------------------------------------------------------------
如果null参与算术运算,则该算术表达式的值为null。(例如:+,-,*,/ 加减乘除)
如果null参与比较运算,则结果可视为false。(例如:>=,<=,<> 大于,小于,不等于)
如果null参与聚集运算,则聚集函数都置为null(使用isnull(字段,0)等方式可以避免这种情况)。除count(*), count(1), count(0)等之外,null行才会计算,注:(count(字段) 字段为null的行不参与计数)。
如果在not in子查询中有null值的时候,则不会返回数据。
1.5 开启事务
01.查看事务
use sys;
select @@autocommit;
02.使用事务
# 开启事务
SET autocommit = 0;
BEGIN;
UPDATE test SET num = 10 WHERE id = '1';
UPDATE test SET num = 10 WHERE var = 1;
# 提交事务
COMMIT;
# 回滚事务
ROLLBACK;
1.6 行列转换
01.行转列
a.数据
a.介绍
基础数据:有学生成绩表,包含学生id、学科、成绩
b.行
student_id subject score
001 语文 89
001 数学 95
001 英语 77
002 语文 92
002 数学 83
002 英语 97
003 语文 81
003 数学 94
003 英语 88
c.列
student_id yuwen shuxue yingyu
001 89 95 77
002 92 83 97
003 81 94 88
b.建表
a.行
CREATE TABLE scores (
student_id VARCHAR(10),
subject VARCHAR(10),
score INT,
PRIMARY KEY (student_id, subject)
);
-------------------------------------------------------------------------------------------------
INSERT INTO scores (student_id, subject, score) VALUES
('001', '语文', 89),
('001', '数学', 95),
('001', '英语', 77),
('002', '语文', 92),
('002', '数学', 83),
('002', '英语', 97),
('003', '语文', 81),
('003', '数学', 94),
('003', '英语', 88);
b.列
CREATE TABLE student_scores (
student_id VARCHAR(10) PRIMARY KEY,
yuwen INT,
shuxue INT,
yingyu INT
);
-------------------------------------------------------------------------------------------------
INSERT INTO student_scores (student_id, yuwen, shuxue, yingyu) VALUES
('001', 89, 95, 77),
('002', 92, 83, 97),
('003', 81, 94, 88);
c.MySQL
INSERT INTO student_scores
SELECT student_id,
SUM(CASE WHEN subject = '语文' THEN SCORE END) AS yuwen,
SUM(CASE WHEN subject = '数学' THEN SCORE END) AS shuxue,
SUM(CASE WHEN subject = '英语' THEN SCORE END) AS yingyu
FROM scores
GROUP BY student_id;
d.Dameng
SELECT student_id,
MAX(CASE WHEN subject = '语文' THEN score END) AS yuwen,
MAX(CASE WHEN subject = '数学' THEN score END) AS shuxue,
MAX(CASE WHEN subject = '英语' THEN score END) AS yingyu
FROM scores
GROUP BY student_id;
e.Dameng
WITH RankedScores AS (
SELECT
student_id,
subject,
score,
ROW_NUMBER() OVER (PARTITION BY student_id ORDER BY subject) AS rn
FROM scores
)
SELECT
student_id,
MAX(CASE WHEN rn = 1 THEN score END) AS yuwen,
MAX(CASE WHEN rn = 2 THEN score END) AS shuxue,
MAX(CASE WHEN rn = 3 THEN score END) AS yingyu
FROM RankedScores
GROUP BY student_id;
02.列转行
a.数据
a.介绍
现有骑手id,订单id列表,订单配送距离列表,配送费列表,其中订单id、配送距离、配送费一一对应
b.列
rider_id order_list distance_list payment_list
r001 0001,0005,0008 8.05,2.32,4.35 17.50,5.00,15.00
r002 0002,0004,0006,0009 3.01,10.98,0.78,5.05,6.05 13.00,15.00,5.00,9.50,7.00
r003 0003,0007 4.12,8.11 13.50,8.00
r004 NULL NULL NULL
c.行
rider_id order_id distance payment
r001 0001 8.05 7.50
r001 0005 2.32 5.00
r001 0008 4.35 15.00
r002 0002 3.01 13.00
r002 0004 10.98 15.00
r002 0006 0.78 5.00
r002 0009 5.05 9.50
r002 0010 6.05 17.00
r003 0003 4.12 3.50
r003 0007 8.11 8.00
r004 NULL NULL NULL
b.建表
a.行
CREATE TABLE riders (
rider_id VARCHAR(10) PRIMARY KEY,
order_list TEXT,
distance_list TEXT,
payment_list TEXT
);
-------------------------------------------------------------------------------------------------
INSERT INTO riders (rider_id, order_list, distance_list, payment_list) VALUES
('r001', '0001,0005,0008', '8.05,2.32,4.35', '17.50,5.00,15.00'),
('r002', '0002,0004,0006,0009', '3.01,10.98,0.78,5.05,6.05', '13.00,15.00,5.00,9.50,7.00'),
('r003', '0003,0007', '4.12,8.11', '13.50,8.00'),
('r004', NULL, NULL, NULL);
b.列
CREATE TABLE rider_details (
rider_id VARCHAR(10),
order_id VARCHAR(10),
distance DECIMAL(10, 2),
payment DECIMAL(10, 2),
PRIMARY KEY (rider_id, order_id)
);
-------------------------------------------------------------------------------------------------
INSERT INTO rider_details (rider_id, order_id, distance, payment) VALUES
('r001', '0001', 8.05, 7.50),
('r001', '0005', 2.32, 5.00),
('r001', '0008', 4.35, 15.00),
('r002', '0002', 3.01, 13.00),
('r002', '0004', 10.98, 15.00),
('r002', '0006', 0.78, 5.00),
('r002', '0009', 5.05, 9.50),
('r002', '0010', 6.05, 17.00),
('r003', '0003', 4.12, 3.50),
('r003', '0007', 8.11, 8.00),
('r004', NULL, NULL, NULL);
c.MySQL
SELECT
r.rider_id,
SUBSTRING_INDEX(SUBSTRING_INDEX(r.order_list, ',', n.n), ',', -1) AS order_id,
SUBSTRING_INDEX(SUBSTRING_INDEX(r.distance_list, ',', n.n), ',', -1) AS distance,
SUBSTRING_INDEX(SUBSTRING_INDEX(r.payment_list, ',', n.n), ',', -1) AS payment
FROM
riders r
JOIN
(SELECT 1 AS n UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5
UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 UNION ALL SELECT 10) n
ON
n.n <= LENGTH(r.order_list) - LENGTH(REPLACE(r.order_list, ',', '')) + 1
WHERE
r.order_list IS NOT NULL
AND r.distance_list IS NOT NULL
AND r.payment_list IS NOT NULL;
d.Dameng
SELECT rider_id,
SUBSTRING_INDEX(SUBSTRING_INDEX(order_list, ',', numbers.n), ',', -1) AS order_id,
SUBSTRING_INDEX(SUBSTRING_INDEX(distance_list, ',', numbers.n), ',', -1) AS distance,
SUBSTRING_INDEX(SUBSTRING_INDEX(payment_list, ',', numbers.n), ',', -1) AS payment
FROM riders
JOIN (SELECT 1 n UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5) numbers
ON CHAR_LENGTH(order_list) - CHAR_LENGTH(REPLACE(order_list, ',', '')) >= numbers.n - 1
WHERE order_list IS NOT NULL;
2 DQL:查
2.1 子句:DISTINCT、WHERE、GROUP BY、HAVING、ORDER BY
范围查询 between
模糊查询 like 数字、字母、日期
分组查询+多行函数/聚合函数/数字函数/组函数 group by
排序查询 order by
-----------------------------------------------------------------------------------------------------
单行函数 字符函数、数值函数、日期函数、转换函数、通用函数
多行函数/聚合函数/数字函数/组函数 从一组记录中返回一条记录,可出现在select列表、ORDER BY和HAVING子句中
TOP/LIMIT/ROWNUM SELECT TOP 数字 列名 FROM 表名
SELECT TOP 百分比 列名 FROM 表名
----------------------------------------------------------------------------------------
SELECT TOP 3 * FROM Customers 获取表的前3条
SELECT TOP 40 Percent * FORM Customers ORDER BY 客户ID DESC 获取表后40%的记录
SELECT TOP 40 Percent * FORM Customers ORDER BY NEWID() 获取随机40%的记录
----------------------------------------------------------------------------------------
SELECT TOP 5 * FROM Customers sqlserver是TOP 5
SELECT * FROM Customers LIMIT 5 mysql是limit 5
SELECT * FROM Customers WHERE ROWNUM <= 5 oracle是where rownum≤5
SELECT子句 SELECT 客户ID,日期 FROM Orders 结果集为列表,返回【对象数组】
DISTINCT子句 SELECT DISTINCT 客户ID,日期 FROM Orders 多列去重,必须保证多列【客户ID+日期】都有相同的值
WHERE子句 SELECT 列名称 FROM 表名 WHERE 列 运算符 值
=
!=
>
<
>=
<=
BETWEEN AND / NOT BETWEEN AND 在某个范围内,查找介于两个值之间的所有数据,包括开始值和结束值,等价于 >= AND <=
LIKE / NOT LIKE 搜索某种模式
_ 下划线表示单个字符
% 百分号表示零个,一个或多个字符
WHERE 地址 LIKE 'a%' 查找以“a”开头的任何值
WHERE 地址 LIKE '%a' 查找以“a”结尾的任何值
WHERE 地址 LIKE '%or%' 在任何位置查找任何具有“or”的值
WHERE 地址 LIKE '_r%' 在第二个位置查找任何具有“r”的值
WHERE 地址 LIKE 'a_%_%' 查找以“a”开头且长度至少为3个字符的值
WHERE 地址 LIKE 'a%o' 找到以"a"开头,以"o"结尾的值
IN / NOT IN 指定针对某个列的多个可能值;允许在WHERE子句种指定多个值,可以理解为OR条件的简写
EXISTS 在子查询中匹配到符合条件的数据行
----------------------------------------------------------------------------------------
select* from emp where mgr = 7788 and job = 'CLERK'; where执行顺序:右->左。先执行job='CLERK',再执行mgr=7788
----------------------------------------------------------------------------------------
SELECT * FROM Customers WHERE ID='5' 错误
SELECT * FROM Customers WHERE ID=5 数字用数值:若使用引号,会触发隐式转换,string字符类型变为int数值类型,查询性能下降,使用不到索引
----------------------------------------------------------------------------------------
SELECT * FROM Customers WHERE 城市=北京 错误
SELECT * FROM Customers WHERE 城市='北京' 文本值用双引号
----------------------------------------------------------------------------------------
SELECT * FROM Customers WHERE 地址 LIKE '花%' 以“花”开头的“地址”的所有用户
SELECT * FROM Customers WHERE 省份 LIKE '%省' 以“省”结尾的“省份”的所有用户
SELECT * FROM Customers WHERE 地址 LIKE '__路%' 地址在第3位是“路”的所有用户
SELECT * FROM Customers WHERE 地址 LIKE '花__%' 地址以“花”开头,且长度至少为3个字符的所有客户
SELECT * FROM Customers WHERE 地址 NOT LIKE '北%' 地址不是以“北”开头的所有用户
SELECT * FROM emp WHERE ename LIKE '_M%' 姓名中第二个字母是M的员工信息:
SELECT * FROM emp WHERE ename LIKE '%M%' 姓名中包含M的员工信息
SELECT * FROM emp WHERE ename LIKE '_______%' 姓名长度>6的员工信息:>6 >=7
----------------------------------------------------------------------------------------
SELECT column_name(s) FROM table_name WHERE column_name IN (value1, value2, ...)
SELECT column_name(s) FROM table_name WHERE column_name IN (SELECT STATEMENT)
SELECT * FROM Customers WHERE ID IN (1,2) ID属于1、2的所有用户
SELECT * FROM Customers WHERE 省份 IN ('上海市', '北京市', '广东省') 查找省份位于'上海市', '北京市', '广东省'的所有客户
SELECT * FROM Customers WHERE 城市 IN (SELECT 城市 FROM Suppliers) 查找供应商(Suppliers)和客户来自同一城市的客户信息
----------------------------------------------------------------------------------------
SELECT column_name(s) FROM table_name WHERE column_name BETWEEN value1 AND value2 范围查询:数字/日期 严格遵照“先小后大”
SELECT * FROM Products WHERE 价格 BETWEEN 30 AND 60 查找价格介于30到60之间的商品
SELECT * FROM Products WHERE 价格 NOT BETWEEN 30 AND 60 查找价格不介于30到60之间的商品
SELECT * FROM Orders WHERE 订单日期 BETWEEN '2018-06-28' AND '2018-09-28' 查找订单日期,介于2018-06-28和2018-09-28之间的所有订单
SELECT * FROM Orders WHERE 订单日期 BETWEEN '2018-06-28 00:00:00' AND '2018-09-28 00:00:00'
----------------------------------------------------------------------------------------
--范围查询:数字/日期 严格遵照“先小后大”
between 小 and 大
>=小 and <=大
--数字
SQL> select * from emp where sal between 1000 and 2000;
EMPNO ENAME JOB MGR HIREDATE
---------- -------------------- ------------------ ---------- -------------- ------
7499 ALLEN SALESMAN 7698 20-2月 -81
7521 WARD SALESMAN 7698 22-2月 -81
SQL> ed
已写入 file afiedt.buf
1* select * from emp where sal between 2000 and 1000
SQL> /
未选定行
--日期
SQL> select * from emp where hiredate between'08-9月 -81' and '22-2月 -81';
未选定行
WHERE子句AND、OR where子语句中,连接多个条件进行过滤
----------------------------------------------------------------------------------------
SELECT * FROM Customers WHERE 姓名='张三' AND 城市='上海' 姓名为 "张三" 并且城市为 "上海" 的人
SELECT * FROM Customers WHERE 姓名='张三' OR 城市='北京' 姓名为 "张三" 或者城市为 "北京" 的人
SELECT * FROM Orders WHERE (客户ID=3 OR 客户ID=1) AND 发货ID=4 客户ID是1或者3,并且两个客户的发货ID都是4的订单信息
SELECT * FROM Orders WHERE 客户ID=3 OR 客户ID=1 AND 发货ID=4 错误
GROUP BY子句 与聚合函数相结合,根据一个或多个列对结果集进行分组
----------------------------------------------------------------------------------------
SELECT 列名, 聚合函数(列名) FROM 表名 WHERE 列 运算符 值 GROUP BY 列名
2 3 1
SELECT 城市,COUNT(*) AS 客户数量 FROM Customers GROUP BY 城市 查询居住在各个城市的客户数量,分别有多少个
SELECT 城市,MAX(客户ID) AS 最大客户ID FROM Customers GROUP BY 城市 不同城市最大的客户ID是多少
----------------------------------------------------------------------------------------
GROUP BY 聚合函数 聚合函数 说明
/ count() 它返回行数,包括一组中具有NULL值的行
数字函数 sum() 它返回集合中的总和(非NULL)
/ avg() 它返回一个表达式的平均值
多行函数 min() 它返回一组中的最小值(最低)
/ max() 它返回集合中的最大值(最高)
组函数 groutp_concat() 它返回一个串联的字符串
first() 它返回表达式的第一个值
last() 它返回表达式的最后一个值
----------------------------------------------------------------------------------------
以下三种形式的count函数:
count(*) 此函数使用SELECT语句返回结果集中的行数。结果集包含所有Non-Null,Null和重复行
count(expression) 该函数返回结果集,但不包含Null行作为结果
count(distinct) 此函数返回不包含NULL值作为表达式结果的不同行的计数。
SELECT COUNT(emp_name) FROM employees; 计算表中可用的员工姓名总数
SELECT COUNT(*) FROM employees WHERE emp_age>32; 该语句返回employee表中的所有行,并且 WHERE子句指定emp_age列中的值大于32的行
SELECT COUNT(DISTINCT emp_age) FROM employees; 使用COUNT(distinct expression)函数对emp_age列中的Non-Null和不同的行进行计数:
SELECT emp_name, city, COUNT(*) FROM employees GROUP BY city; 带有GROUP BY子句的MySQL Count()函数:返回每个城市的雇员人数
SELECT emp_name, emp_age, COUNT(*) FROM employees GROUP BY emp_age HAVING COUNT(*)>=2 ORDER BY COUNT(*); 带有HAVING和ORDER BY子句的MySQL Count()函数:给出至少两个相同年龄的员工姓名,并根据计数结果对他们进行排序
----------------------------------------------------------------------------------------
SELECT SUM(working_hours) AS "Total working hours" FROM employees; 计算表中所有员工的总工作时间
SELECT SUM(working_hours) AS "Total working hours" FROM employees WHERE working_hours>=12; 带有WHERE子句的MySQL sum()函数:查询以计算 working_hours> = 12 的员工的总工作时间
SELECT emp_id, emp_name, occupation, SUM(working_hours) AS "Total working hours" FROM employees; 带有GROUP BY子句的MySQL sum()函数:计算每个员工的总工作时间
SELECT emp_id, emp_name, occupation, SUM(working_hours) Total_working_hours FROM employees GROUP BY occupation HAVING SUM(working_hours)>24; 带有HAVING子句的MySQL sum()函数:计算所有员工的工作时间,并根据他们的职业对其进行分组,并返回结果,其结果为Total_working_hours> 24
SELECT emp_name, occupation, SUM(DISTINCT working_hours) Total_working_hours FROM employees GROUP BY occupation; 带有DISTINCT子句的MySQL sum()函数:删除表中work_hours列中的重复记录。员工表,然后计算总和
----------------------------------------------------------------------------------------
SELECT AVG(working_hours) Avg_working_hours FROM employees; 计算表中所有员工的 平均工作时间:
SELECT AVG(working_hours) Avg_working_hours FROM employees WHERE working_hours>=12; 计算 working_hours> = 12 的员工的平均总工作时间
SELECT emp_name, occupation, AVG(working_hours) Avg_working_hours FROM employees GROUP BY occupation; 带有GROUP BY子句的MySQL AVG()函数:计算每个员工的平均工作时间,然后将结果与GROUP BY子句分组
SELECT emp_name, occupation, AVG(working_hours) Avg_working_hours FROM employees GROUP BY occupation HAVING AVG(working_hours)>9; 带有HAVING子句的MySQL AVG()函数:计算所有员工的平均工作时间,根据他们的职业对他们进行分组,并返回结果 Avg_working_hours> 9
SELECT emp_name, occupation, AVG(DISTINCT working_hours) Avg_working_hours FROM employees GROUP BY occupation; 带有DISTINCT子句的MySQL AVG()函数:以删除employee表中的重复记录然后返回平均值
----------------------------------------------------------------------------------------
SELECT MIN(income) AS Minimum_Income FROM employees; 找到表中可用的员工的 最低收入
SELECT MIN(income) AS Minimum_Income FROM employees WHERE emp_age >= 32 AND emp_age <= 40; 带有WHERE子句的MySQL MIN()函数:从employee表中查找所有行中的最低收入,WHERE子句指定 emp_age列大于或等于32且小于或等于40的所有行
SELECT emp_age, MIN(income) AS Minimum_Income FROM employees GROUP BY emp_age; 带有GROUP BY子句的MySQL MIN()函数:查找employee表中每个emp_age组的所有行中的最低收入
SELECT city, MIN(income) AS Minimum_Income FROM employees GROUP BY city HAVING MIN(income) > 150000; 带有HAVING子句的MySQL MIN()函数:返回所有雇员的最低收入,根据他们的城市将他们分组,并返回MIN(收入)> 150000的结果
SELECT emp_name, city, MIN(DISTINCT income) AS Minimum_Income FROM employees GROUP BY city; 带有DISTINCT子句的MySQL MIN()函数:返回表中存在的唯一记录数的最小收入值
----------------------------------------------------------------------------------------
SELECT MAX(income) AS "Maximum Income" FROM employees; 找到表中可用的员工的最高收入:
SELECT MAX(income) AS "Maximum_Income" FROM employees WHERE emp_age > 35; 带有WHERE子句的MySQL MAX()函数:在employee表中的所有行中查找最大收入。 WHERE子句指定 emp_age列大于35的所有行
SELECT emp_age, MAX(income) AS "Maximum Income" FROM employees GROUP BY emp_age; 带有GROUP BY子句的MySQL MAX()函数:从employee表的所有行中找到每个emp_age组的最大收入
SELECT city, MAX(income) AS "Maximum Income" FROM employees GROUP BY city HAVING MAX(income) >= 200000; 带有HAVING子句的MySQL MAX()函数:返回所有雇员中的最大收入,并根据他们所在的城市对其进行分组,并返回其MAX(income)> = 200000的结果
SELECT city, MAX(DISTINCT income) AS "Maximum Income" FROM employees GROUP BY city; 带有DISTINCT子句的MySQL MAX()函数:以删除employee表的income列中的重复记录,按城市分组,然后返回最大值
SELECT * FROM employees WHERE emp_age = (SELECT MAX(emp_age) FROM employees); 子查询示例中的MySQL MAX()函数:子查询首先从表中找到雇员的最大年龄。然后,主查询(外部查询)返回的年龄等于从子查询返回的最大年龄以及其他信息。
日期函数 DATE() 返回日期部分,去除时间部分
TIME() 返回时间部分,去除日期部分
NOW() 或 CURRENT_TIMESTAMP 返回当前日期和时间
----------------------------------------------------------------------------------------
YEAR() 返回日期或日期时间值的年份
MONTH() 返回日期或日期时间值的月份
DAY() 返回日期或日期时间值的天数
HOUR() 返回日期或日期时间值的小时
MINUTE() 返回日期或日期时间值的分钟
SECOND() 返回日期或日期时间值的秒数
----------------------------------------------------------------------------------------
DATE_FORMAT() 格式化日期或日期时间值为特定的字符串表示
DATE_ADD() 增加或减少日期或日期时间值中的特定时间间隔
DATEDIFF() 计算两个日期之间的天数差异
DATEPART() 或 EXTRACT() 提取日期或日期时间值中的特定部分,如年、月、日等
DAYNAME() 返回日期或日期时间值对应的星期几的名称
MONTHNAME() 返回日期或日期时间值对应的月份的名称
WEEK() 返回日期或日期时间值对应的年份中的周数
CAST() 将字符串转换为日期或日期时间类型
STR_TO_DATE() 将字符串按照指定格式转换为日期或日期时间类型
常用字符处理函数 CONCAT() 或 || 将多个字符串连接成一个字符串
LENGTH() 或 LEN() 返回字符串的长度
SUBSTRING() 或 SUBSTR() 从字符串中提取子字符串
UPPER() 或 UCASE() 将字符串转换为大写
LOWER() 或 LCASE() 将字符串转换为小写
TRIM() 去除字符串两端的空格或指定的字符
LTRIM() 去除字符串左侧的空格或指定的字符
RTRIM() 去除字符串右侧的空格或指定的字符
REPLACE() 替换字符串中的指定子字符串
REVERSE() 反转字符串
LEFT() 返回字符串左侧的指定字符数
RIGHT() 返回字符串右侧的指定字符数
CHARINDEX() 或 INSTR() 查找子字符串在字符串中的位置
LPAD() 在字符串左侧填充指定字符
RPAD() 在字符串右侧填充指定字符
INITCAP() 将字符串的首字母转换为大写,其他字母转换为小写
CONCAT_WS() 使用指定的分隔符连接多个字符串,并去除空值
HAVING子句 对分组后的数据进一步过滤,找出符合分组条件的记录
----------------------------------------------------------------------------------------
SELECT 列名, 聚合函数(列名) FROM 表名 WHERE 列 运算符 值 GROUP BY 列名 HAVING COUNT(1)>1
2 3 1 4
SELECT 城市, COUNT(*) AS 客户数量 FROM Customers GROUP BY 城市 HAVING COUNT (1)>1 查询居住在各个城市的客户数量,大于或等于2的所有记录
SELECT 城市, COUNT(*) AS 客户数量 FROM Customers GROUP BY 城市 HAVING COUNT (1)>1 AND 城市!='南京' 查询居住在各个城市(不包括南京)的客户数量,大于或等于2的所有记录
ORDER BY子句 HAVING子句必须紧随GROUP BY子句,并出现在ORDER BY子句之前
对结果集进行排序,按照【省份】拼音首字母的ASCII规则排序;字母相同,则比较第二位字母,依次类推
----------------------------------------------------------------------------------------
SELECT 列名, 聚合函数(列名) FROM 表名 WHERE 列 运算符 值 GROUP BY 列名 HAVING COUNT(1)>1 ORDER BY 列1 ASC升序, 列2 DESC降序
5 2 3 1 4 6 7
SELECT * FROM Customers 省份 ASC, 姓名 DESC 按照省份升序、姓名降序的规则,对客户进行排序
2.2 集合运算:UNION
2.2.1 并集、交集、差集
UNION 组合两个或更多SELECT语句的结果集
使用前提:UNION中的每个SELECT语句必须具有相同的列数
1、这些列也必须具有相似的数据类型
2、每个SELECT语句中的列也必须以相同的顺序排列
----------------------------------------------------------------------------------------
UNION(并集):返回各个查询的所有记录,不包括重复记录。
UNION ALL(并集):返回各个查询的所有记录,包括重复记录。
INTERSECT(交集):返回两个查询共有的记录。
MINUS(差集):返回包含在第一个查询中,但不包含在第二个查询中的记录。
----------------------------------------------------------------------------------------
SELECT column_name(s) FROM table1
UNION (ALL)
SELECT column_name(s) FROM table2
注意:UNION结果集中的列名总是等于UNION中第一个SELECT语句中的列名
----------------------------------------------------------------------------------------
SELECT 城市 FROM customers_bak 从“customers_bak”和“Suppliers”表中选择所有不同的城市(只有不同的值)
UNION
SELECT 城市 FROM Suppliers
SELECT 城市 FROM customers_bak 从“customers_bak”和“Suppliers”表中选择所有不同的城市(可以有重复值)
UNION ALL
SELECT 城市 FROM Suppliers
2.2.2 各个集合的列数、类型必须保持一致
-- 各个集合的列数、类型必须保持一致
select empno,ename from emp --数字 字符串 2列
union
select deptno,job from emp; --数字 字符串 2列
SQL> select empno from emp
2 union
3 select deptno,job from emp;
select empno from emp
*
第 1 行出现错误:
ORA-01789: 查询块具有不正确的结果列数
-- 查询所有领取奖金和不领取奖金的员工人数、平均工资
-- 错误 (分组不明确,有300,500,1000,无奖金)
select count(*),avg(sal)
from emp
group by comm ;
-- 重新读题
select count(*),avg(sal)
from emp where comm is not null and comm > 0
union
select count(*),avg(sal)
from emp where comm is null or comm = 0;
COUNT(*) AVG(SAL)
---------- ----------
6 5682.33333
13 2265.90909
-- 查询所有教师和同学的name、sex和birthday
SELECT name, sex, birthday FROM teacher
UNION
SELECT name, sex, birthday FROM student;
+--------+-----+------------+
| name | sex | birthday |
+--------+-----+------------+
| 李诚 | 男 | 1958-12-02 |
| 王萍 | 女 | 1972-05-05 |
| 刘冰 | 女 | 1977-08-14 |
| 张旭 | 男 | 1969-03-12 |
| 曾华 | 男 | 1977-09-01 |
| 匡明 | 男 | 1975-10-02 |
| 王丽 | 女 | 1976-01-23 |
| 李军 | 男 | 1976-02-20 |
| 王芳 | 女 | 1975-02-10 |
| 陆军 | 男 | 1974-06-03 |
| 王尼玛 | 男 | 1976-02-20 |
| 张全蛋 | 男 | 1975-02-10 |
| 赵铁柱 | 男 | 1974-06-03 |
+--------+-----+------------+
-- 查询所有“女”教师和“女”同学的name、sex和birthday
SELECT name, sex, birthday FROM teacher where sex='女'
UNION
SELECT name, sex, birthday FROM student where sex='女';
+------+-----+------------+
| name | sex | birthday |
+------+-----+------------+
| 王萍 | 女 | 1972-05-05 |
| 刘冰 | 女 | 1977-08-14 |
| 王丽 | 女 | 1976-01-23 |
| 王芳 | 女 | 1975-02-10 |
+------+-----+------------+
-- 在计算机系的职称中与电子工程系职称不同的教师
SELECT * FROM teacher WHERE department = '计算机系' AND profession NOT IN (
SELECT profession FROM teacher WHERE department = '电子工程系'
);
+-----+------+-----+------------+------------+------------+
| no | name | sex | birthday | profession | department |
+-----+------+-----+------------+------------+------------+
| 804 | 李诚 | 男 | 1958-12-02 | 副教授 | 计算机系 |
+-----+------+-----+------------+------------+------------+
-- 在电子工程系的职称中与计算机系职称不同的教师
SELECT * FROM teacher WHERE department = '电子工程系' AND profession NOT IN (
SELECT profession FROM teacher WHERE department = '计算机系'
);
+-----+------+-----+------------+------------+------------+
| no | name | sex | birthday | profession | department |
+-----+------+-----+------------+------------+------------+
| 856 | 张旭 | 男 | 1969-03-12 | 讲师 | 电子工程系 |
+-----+------+-----+------------+------------+------------+
-- NOT IN: 代表逻辑非
-- UNION:合并两个集
-- 查询 计算机系 与 电子工程系 中的不同职称的教师
SELECT * FROM teacher WHERE department = '计算机系' AND profession NOT IN (
SELECT profession FROM teacher WHERE department = '电子工程系'
)
UNION
SELECT * FROM teacher WHERE department = '电子工程系' AND profession NOT IN (
SELECT profession FROM teacher WHERE department = '计算机系'
);
+-----+------+-----+------------+------------+------------+
| no | name | sex | birthday | profession | department |
+-----+------+-----+------------+------------+------------+
| 804 | 李诚 | 男 | 1958-12-02 | 副教授 | 计算机系 |
| 856 | 张旭 | 男 | 1969-03-12 | 讲师 | 电子工程系 |
+-----+------+-----+------------+------------+------------+
2.3 多表连接:JOIN
JOIN JOIN 连接用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。
最常见的 JOIN 类型:INNER JOIN(简单的 JOIN)。
INNER JOIN 从多个表中返回满足 JOIN 条件的所有行
----------------------------------------------------------------------------------------
CROSS JOIN 交叉连接/笛卡儿积 其他4种都是以笛卡儿积为基准
INNER JOIN 内连接 如果表中有至少一个匹配,则返回行
LEFT JOIN 左连接 即使右表中没有匹配,也从左表返回所有的行
RIGHT JOIN 右连接 即使左表中没有匹配,也从右表返回所有的行
FULL JOIN 全连接 只要其中一个表中存在匹配,则返回行
----------------------------------------------------------------------------------------
SELECT column_name(s) SELECT A.NUM_A, B.NUM_B 交叉连接/笛卡儿积(CROSS JOIN)
FROM table1 FROM A
CROSS JOIN table2 CROSS JOIN B
ON table1.column_name = table2.column_name; ON A.Num_A = B.NUM_B
SELECT column_name(s) SELECT A.NUM_A, B.NUM_B 内连接(INNER JOIN) 等价于 SELECT A.NUM_A, B.NUM_B
FROM table1 FROM A FROM A,B
INNER JOIN table2 INNER JOIN B WHERE A.name = B.name
ON table1.column_name = table2.column_name; ON A.Num_A = B.NUM_B
SELECT column_name(s) SELECT A.NUM_A, B.NUM_B 左连接(LEFT JOIN)
FROM table1 FROM A A主表
LEFT JOIN table2 LEFT JOIN B
ON table1.column_name=table2.column_name; ON A.Num_A = B.NUM_B
SELECT column_name(s) SELECT A.NUM_A, B.NUM_B 右连接(RIGHT JOIN )
FROM table1 FROM A B主表
RIGHT JOIN table2 RIGHT JOIN B
ON table1.column_name = table2.column_name; ON A.Num_A = B.NUM_B
SELECT column_name(s) SELECT A.NUM_A, B.NUM_B 全连接(FULL JOIN)=左连接+右连接+去重
FROM table1 FROM A
FULL JOIN table2 FULL JOIN B
ON table1.column_name = table2.column_name; ON A.Num_A = B.NUM_B
01.表连接方式
不同的数据分析工具 支持的表连接方式
Oracle/ sql server/ Tableau/ Python 内连接(inner join)、左连接(left join)、右连接(right join)、全连接(full join)
MySQL 内连接(inner join)、左连接(left join)、右连接(right join)
Power BI 内连接、左连接、右连接、全连接、左反连接、右反连接
2.3.1 交叉连接(笛卡儿积)
select * from emp, dept;
select * from emp cross join dept;
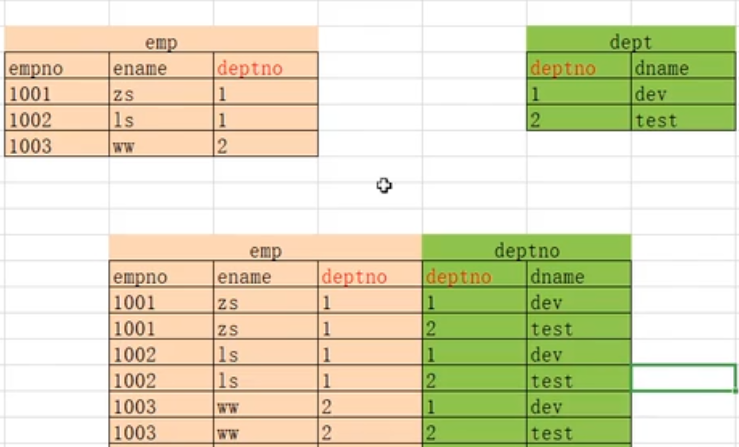
2.3.2 内连接
-- INNER JOIN: 表示为内连接,将两张表拼接在一起。
-- on: 表示要执行某个条件。
SELECT * FROM person INNER JOIN card on person.cardId = card.id;
+------+--------+--------+------+-----------+
| id | name | cardId | id | name |
+------+--------+--------+------+-----------+
| 1 | 张三 | 1 | 1 | 饭卡 |
| 2 | 李四 | 3 | 3 | 农行卡 |
+------+--------+--------+------+-----------+
-- 将 INNER 关键字省略掉,结果也是一样的。
-- SELECT * FROM person JOIN card on person.cardId = card.id;
-- 多张表通过相同字段进行匹配,只显示匹配成功的数据
-- 等值连接
a. select * from emp e ,dept d 只有where
where e.deptno = d.deptno;
b. select * from emp e 有inner join on
inner join dept d
on e.deptno = d.deptno
c. select * from emp e 只有join on
join dept d
on e.deptno = d.deptno
-- 不等值连接(一般不用)
select * from emp e ,dept d
where e.deptno != d.deptno ;
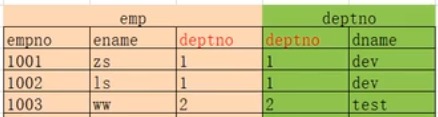
2.3.3 左连接
-- 完整显示左边的表 (person) ,右边的表如果符合条件就显示,不符合则补 NULL
-- LEFT JOIN 也叫做 LEFT OUTER JOIN,用这两种方式的查询结果是一样的。
SELECT * FROM person LEFT JOIN card on person.cardId = card.id;
+------+--------+--------+------+-----------+
| id | name | cardId | id | name |
+------+--------+--------+------+-----------+
| 1 | 张三 | 1 | 1 | 饭卡 |
| 2 | 李四 | 3 | 3 | 农行卡 |
| 3 | 王五 | 6 | NULL | NULL |
+------+--------+--------+------+-----------+
-- 以左表为基准(左表数据全部显示),去匹配右表数据
-- 如果匹配成功,则全部显示;匹配不成功,显示部分(无数据部分 用NULL填充)
a.(oracle独有)
select * from emp e ,dept d
where e.deptno = d.deptno(+) ;
b. select * from emp e
left join dept d
on e.deptno = d.deptno
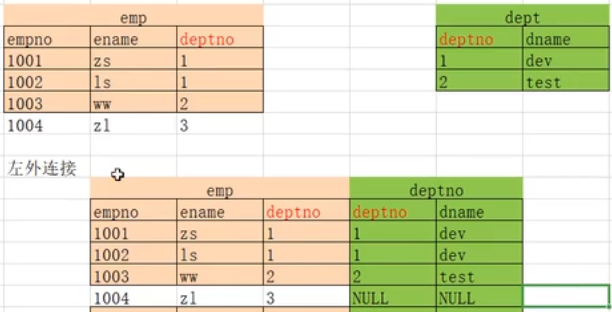
2.3.4 右连接
-- 完整显示右边的表 (card) ,左边的表如果符合条件就显示,不符合则补 NULL
SELECT * FROM person RIGHT JOIN card on person.cardId = card.id;
+------+--------+--------+------+-----------+
| id | name | cardId | id | name |
+------+--------+--------+------+-----------+
| 1 | 张三 | 1 | 1 | 饭卡 |
| 2 | 李四 | 3 | 3 | 农行卡 |
| NULL | NULL | NULL | 2 | 建行卡 |
| NULL | NULL | NULL | 4 | 工商卡 |
| NULL | NULL | NULL | 5 | 邮政卡 |
+------+--------+--------+------+-----------+
-- 以右表为基准(右表数据全部显示),去匹配左表数据
-- 如果匹配成功,则全部显示;匹配不成功,显示部分(无数据部分 用NULL填充)
a.(oracle独有)
select * from emp e ,dept d
where e.deptno(+) = d.deptno;
b. select * from emp e
right join dept d
on e.deptno = d.deptno
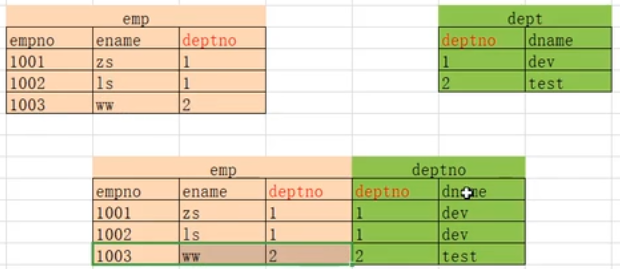
2.3.5 全连接=左连接+右连接+去重
-- MySQL 不支持这种语法的全外连接
-- SELECT * FROM person FULL JOIN card on person.cardId = card.id;
-- 出现错误:
-- ERROR 1054 (42S22): Unknown column 'person.cardId' in 'on clause'
-- MySQL全连接语法,使用 UNION 将两张表合并在一起。
SELECT * FROM person LEFT JOIN card on person.cardId = card.id
UNION
SELECT * FROM person RIGHT JOIN card on person.cardId = card.id;
+------+--------+--------+------+-----------+
| id | name | cardId | id | name |
+------+--------+--------+------+-----------+
| 1 | 张三 | 1 | 1 | 饭卡 |
| 2 | 李四 | 3 | 3 | 农行卡 |
| 3 | 王五 | 6 | NULL | NULL |
| NULL | NULL | NULL | 2 | 建行卡 |
| NULL | NULL | NULL | 4 | 工商卡 |
| NULL | NULL | NULL | 5 | 邮政卡 |
+------+--------+--------+------+-----------+
2.3.6 自连接
01.两层自连接
SELECT b.*
from shopping as a,shopping as b
where a.name='惠惠'
and a.price<b.price
order by b.id
02.三层自连接查询
SELECT c.dept_name area, b.dept_name as city, a.*
from sys_dept as a, sys_dept as b, sys_dept as c
where a.parent_id= b.dept_id
and b.parent_id= c.dept_id
and a.agency_id >= -1
order by b.dept_id
01.查询所有员工的编号、姓名,及其上级领导的编号、姓名, 显示结果按领导的年工资降序
a.要查询哪些字段、表
员工表e.empno, 员工表e.ename, 领导表b.empno, 领导表b.ename
emp e,emp b
b.连接条件
e.mgr = b.empno
order by b.sal*12+nvl(comm, 0) desc;
02.自连接
select e.empno, e.ename, b.empno, b.ename
from emp e, emp b
where e.mgr = b.empno
order by b.sal*12+nvl(b.comm, 0) desc;
2.4 子查询/内查询/嵌套查询
2.4.1 概念
01.什么是子查询
子查询(Sub Query)或者说内查询(Inner Query),也可以称作嵌套查询(Nested Query),是一种嵌套在其他 SQL 查询的 WHERE 子句中的查询。
子查询用于为主查询返回其所需数据,或者对检索数据进行进一步的限制。
子查询可以在 SELECT、INSERT、UPDATE 和 DELETE 语句中,同 =、<、>、>=、<=、IN、BETWEEN 等运算符一起使用
02.使用子查询必须遵循以下几个规则:
1、子查询必须括在圆括号中
2、子查询的 SELECT 子句中只能有一个列,除非主查询中有多个列,用于与子查询选中的列相比较
3、子查询不能使用 ORDER BY,不过主查询可以。在子查询中,GROUP BY 可以起到同 ORDER BY 相同的作用
4、返回多行数据的子查询只能同多值操作符一起使用,比如 IN 操作符
5、SELECT 列表中不能包含任何对 BLOB、ARRAY、CLOB 或者 NCLOB 类型值的引用
6、子查询不能直接用在集合函数中
7、BETWEEN 操作符不能同子查询一起使用,但是 BETWEEN 操作符可以用在子查询中
2.4.2 分类
00.子查询分类
a.按照查询的返回结果
单行单列(标量子查询):返回的是一个具体列的内容,可以理解为一个单值数据
单行多列(行子查询):返回一行数据中多个列的内容
多行单列(列子查询):返回多行记录之中同一列的内容,相当于给出了一个操作范围
多行多列(表子查询):查询返回的结果是一张临时表
b.按子查询位置区分
select后的子查询:仅仅支持标量子查询,即只能返回一个单值数据。
from型子查询:把内层的查询结果当成临时表,供外层sql再次查询,所以支持的是表子查询。
where或having型子查询:指把内部查询的结果作为外层查询的比较条件,支持标量子查询(单列单行)、列子查询(单列多行)、行子查询(多列多行)。
一般会和下面这几种方式配合使用:
1)in子查询:内层查询语句仅返回一个数据列,这个数据列的值将供外层查询语句进行比较
2)any子查询:只要满足内层子查询中的任意一个比较条件,就返回一个结果作为外层查询条件
3)all子查询:内层子查询返回的结果需同时满足所有内层查询条件
4)比较运算符子查询:子查询中可以使用的比较运算符如 >、>=、<=、<、=、 <>
exists子查询:把外层的查询结果(支持多行多列),拿到内层,看内层是否成立,简单来说后面的返回true,外层(也就是前面的语句)才会执行,否则不执行。
01.分类1
a.SELECT子查询语句
SELECT column_name [,column_name]
FROM table1 [,table2]
WHERE column_name OPERATOR
(SELECT column_name [,column_name]
FROM table1 [,table2 ]
[WHERE])
SELECT * FROM Customers
WHERE 客户 ID IN (
SELECT 客户 ID FROM Orders WHERE 员工 ID=9
);
b.INSERT子查询语句
INSERT INTO
table_name [(column1 [,column2])]
SELECT [*|column1 [,column2]
FROM table1 [,table2]
[WHERE VALUE OPERATOR]
INSERT INTO Customers_bak
SELECT * FROM Customers
WHERE 客户 ID IN (
SELECT 客户 ID FROM Orders WHERE 员工 ID=9
);
c.UPDATE子查询语句
UPDATE table
SET column_name = new_value
[WHERE OPERATOR [VALUE]
(SELECT COLUMN_NAME
FROM TABLE_NAME)
[WHERE)]
UPDATE Customers
SET 城市=城市+'市'
WHERE 客户 ID IN (
SELECT 客户 ID FROM Orders
);
d.DELETE子查询语句
DELETE FROM TABLE_NAME
[ WHERE OPERATOR [VALUE]
(SELECT COLUMN_NAME
FROM TABLE_NAME)
[WHERE)]
DELETE FROM Customers
WHERE 客户 ID IN (
SELECT 客户 ID FROM Orders
)
02.分类2
a.SELECT语句中的子查询
a.标量子查询
SELECT column1, (SELECT MAX(column2) FROM table2) AS max_value
FROM table1;
b.列子查询
SELECT column1
FROM table1, (SELECT column2 FROM table2) AS subquery
WHERE table1.column3 = subquery.column2;
c.行子查询
SELECT column1, column2
FROM table1
WHERE (column1, column2) IN (SELECT column1, column2 FROM table2);
d.表子查询
SELECT *
FROM (SELECT column1, column2 FROM table1) AS subquery;
b.INSERT语句中的子查询
a.标量子查询
INSERT INTO table1 (column1)
VALUES ((SELECT MAX(column2) FROM table2));
b.列子查询
INSERT INTO table1 (column1)
SELECT column2 FROM table2;
c.UPDATE语句中的子查询
a.标量子查询
UPDATE table1
SET column1 = (SELECT MAX(column2) FROM table2)
WHERE column3 = 'some_value';
b.列子查询
UPDATE table1
SET column1 = (SELECT column2 FROM table2 WHERE table2.id = table1.id);
d.DELETE语句中的子查询
a.标量子查询
DELETE FROM table1
WHERE column1 = (SELECT MIN(column2) FROM table2);
b.列子查询
DELETE FROM table1
WHERE column1 IN (SELECT column2 FROM table2);
2.4.3 子查询中的null
-- NULL:自身特性,如果!=NULL,则无法查询出任何数据
-- 子查询的结果中不要有NULL!!
-- in: = or = or
select *from emp where mgr in (7566,7698); //有值
select *from emp where mgr in (7566,7698,NULL); //有值,null对结果无影响
理解:select *from emp where mgr =7566 or mgr=7698 or mgr = NULL;
-- not in: =and =and
select *from emp where mgr not in (7566,7698,NULL); //无值
理解:select *from emp where mgr!=7566 and mgr!=7698 and mgr!= NULL ;
-- 子查询的结果中不要有NULL!!
is null
is not null
= null //不正规
!= null //不正规
SQL> select * from emp where empno is not NULL;
EMPNO ENAME JOB MGR HIREDATE
---------- -------------------- ------------------ ---------- -------------- ------
7369 SMITH CLERK 7902 17-12月-80
7499 ALLEN SALESMAN 7698 20-2月 -81
SQL> select * from emp where empno!=NULL;
未选定行
2.4.4 主查询与子查询
-- 主查询和子查询可以是同一张表,也可以不同一张表
-- 查询销售部的员工信息
1.现根据“销售部”查询 销售部的部门编号30
select deptno from dept where dname = 'DNAME' ;
2.根据部门编号30 查询员工信息
select * from emp
where deptno = (select deptno from dept where dname = 'DNAME' );
2.4.4.1 单行操作符(=,>,<)
-- 查询工资比30号部门中 任意其中一个(存在)员工高的员工信息
"只需要满足一个即可,存在一个就可以" -> any
select *from emp where sal > any(select sal from emp) ;
或
select *from emp where sal > (select min(sal) from emp) ;
-- 查询工资比30号部门中全部员工高的(存在)员工信息
"所有、全部" -> all
select *from emp where sal > all(select sal from emp) ;
或
select *from emp where sal > (select max(sal) from emp) ;
2.4.4.2 多行操作符(in)
-- 子查询可以使用 单行操作符(=,<),多行操作符(in)
-- 多行操作符(in): 查询销售部,财务部的员工信息
SQL> select * from emp where deptno in
(select deptno from dept where dname = 'SALES' or dname='ACCOUNTING');
EMPNO ENAME JOB MGR HIREDATE
---------- -------------------- ------------------ ---------- -------------- ----
7782 CLARK MANAGER 7839 09-6月 -81
7839 KING PRESIDENT 17-11月-81
SQL> select deptno from dept where dname = 'SALES' or dname='ACCOUNTING';
DEPTNO
----------
10
30
SQL> select * from emp where deptno =
(select deptno from dept where dname = 'SALES' or dname='ACCOUNTING');
ORA-01427: 单行子查询返回多个行
3 DML:增、改、删
3.1 增:INSERT INTO
3.1.1 单条插入
INSERT INTO 向表里面插入数据记录
----------------------------------------------------------------------------------------
INSERT INTO table_name VALUES (value1, value2, value3, ...)
INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...)
----------------------------------------------------------------------------------------
INSERT INTO Customers VALUES ('宋江','梁山路1号','济南','250000','山东省');
INSERT INTO Customers (姓名, 城市, 省份) VALUES ('武松', '邢台', '河北省');
INSERT INTO Customers (姓名, 地址, 城市, 邮编, 省份) VALUES ('宋江','梁山路1号','济南','250000','山东省');
3.1.2 批量插入
INSERT INTO 向表里面插入数据记录
----------------------------------------------------------------------------------------
INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...),
(value1, value2, value3, ...),
(value1, value2, value3, ...),
(value1, value2, value3, ...);
SELECT INTO 从一个表中复制数据,然后将数据插入到另一个新表中。这种用法只有SQL Server数据库才支持
SELECT * INTO newtable [IN externaldb] FROM table1; 把所有的列都复制到新表中
SELECT column_name(s) INTO newtable [IN externaldb] FROM table1;
----------------------------------------------------------------------------------------
SELECT * INTO CustomersBak FROM Customers; 备份表
SELECT * FROM CustomerBak;
DROP TABLE CustomerBak;
----------------------------------------------------------------------------------------
SELECT * INTO CustomersHis FROM Customers WHERE 1=0; 复制表结构
SELECT * FROM CustomersHis;
DROP TABLE CustomersHis;
INSERT INTO SELECT 在旧表中插入(已存在的表)
从表中复制数据,并将数据插入现有的表中。目标表中的任何现有行都不会受到影响。这种写法在多个数据库平台都支持。
INSERT INTO table2 SELECT * FROM table1; 将所有列从一个表中复制到另一个已经存在的表
INSERT INTO table2 (column_name(s)) SELECT column_name(s) FROM table1; 把想要的列复制到另一个现有的表
注意:table1和table2的表结构的列数和对应字段类型要一致
----------------------------------------------------------------------------------------
INSERT INTO CustomersHis SELECT * FROM Customers; 从Customers中插入到CustomersHis
CREATE TABLE AS 创建新表(批量插入之前不存在)
----------------------------------------------------------------------------------------
create table mytab as select * from emp; 批量插入
create table mytab2 as select empno,ename,job from emp; 批量插入
create table mytab3 as select empno,ename,job from emp where sal < 6000; 批量插入
----------------------------------------------------------------------------------------
create table mytab4 as select * from emp where 1=0 ; 创建表结构
begin ... end / begin
insert into emp values(1221,'LISI','MANAGER',7788,'19-9月 -88',9998,1000,10);
insert into emp values(1223,'LISI','MANAGER',7788,'19-9月 -88',9998,1000,10);
end;
/
海量数据 数据泵 / SQL Loader / 外部表
3.2 改:UPDATE
3.2.1 单条更新
UPDATE 用于更新表中的现有记录
----------------------------------------------------------------------------------------
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;
UPDATE Customers SET 姓名= '鲁智深',城市= '平凉',省份='甘肃省' WHERE 姓名 ='张三'; 第一个客户(姓名=’张三’)更新了"姓名","城市"以及"省份"
----------------------------------------------------------------------------------------
SELECT * INTO #Customers FROM Customers 备份表到#Customers
SELECT * FROM #Customers
UPDATE USERS SET NAME=FAX 把一个列的值复制成另一个列的值
UPDATE #Customers SET 姓名='宋江'; 危险操作,更新表里的所有信息
注意:
要注意SQL UPDATE语句中的WHERE子句!
WHERE子句指定哪些记录需要更新。如果省略WHERE-子句,所有记录都将更新!
3.2.2 批量更新
01.replace into 批量更新
replace into test_tbl (id,dr) values (1,'2'),(2,'3'),...(x,'y');
02.insert into ... on duplicate key update批量更新
insert into test_tbl (id,dr) values (1,'2'),(2,'3'),...(x,'y') on duplicate key update dr=values(dr);
03.创建临时表,先更新临时表,然后从临时表中update
create temporary table tmp(id int(4) primary key,dr varchar(50));
insert into tmp values (0,'gone'), (1,'xx'),...(m,'yy');
update test_tbl, tmp set test_tbl.dr=tmp.dr where test_tbl.id=tmp.id;
04.使用mysql 自带的语句构建批量更新
UPDATE tableName
SET orderId = CASE id
WHEN 1 THEN 3
WHEN 2 THEN 4
WHEN 3 THEN 5
END
WHERE id IN (1,2,3)
-------------------------------------------------------------------------------------------------------------
MERGE INTO MW_APP.MWT_UD_TEST_CLASS t USING (
SELECT 'C001' AS CODE, '001' AS REMARK FROM DUAL UNION
SELECT 'C003' AS CODE, '003' AS REMARK FROM DUAL UNION
SELECT 'C005' AS CODE, '005' AS REMARK FROM DUAL
) f ON (t.CODE=f.CODE)
WHEN MATCHED THEN
UPDATE SET t.REMARK=f.REMARK
WHEN NOT MATCHED THEN
INSERT(OBJ_ID, OBJ_DISPIDX, CODE, REMARK)
VALUES(my_sys.newguid(), 0, f.CODE, f.REMARK);
3.3 删:DELETE、TRUNCATE、DROP
1. delete from emp; 可以回退
truncate table emp; 不能回退
原因:
DDL:数据定义语言 create drop truncate alter --> 不可以回退(可以进行事务操作)
DML:数据操作语言 insert delete update --> 可以回退(可以进行事务操作)
2. 测试二者执行时间
打开执行时间:set timing on/off
对于少量数据: delete效率高,一行一行删除
对于海量数据: truncate效率高,a.drop table 丢弃整张表
b.重新创建表
3. delete支持闪回,truncate不支持闪回
4. delete不会释放空间(换两个地方存储数据[undo空间],回收站),trucante会释放空间(清空回收站)
5. delete会产生碎片,trunate不会产生碎片
如果碎片太多,需要整理碎片: a.alter table 表名 move;
b.导出导入

3.3.1 DELETE
DELETE 用于删除表中现有记录
----------------------------------------------------------------------------------------
DELETE FROM table_name WHERE condition;
DELETE FROM #Customers WHERE 姓名='张三' 删除姓名为“张三”的用户信息
----------------------------------------------------------------------------------------
SELECT * #Customers FROM Customers; 备份表到#Customers
DELETE FROM #Customers 危险操作,删除表里的所有信息
注意:
删除表格中的记录时要小心!
注意 SQL DELETE 语句中的 WHERE 子句!
WHERE 子句指定需要删除哪些记录。如果省略了 WHERE 子句,表中所有记录都将被删除!
DELETE DELETE FROM myorder; 清空某个表的所有数据
3.3.2 TRUNCATE
TRUNCATE TRUNCATE TABLE myorder; 截断表;删除表的所有行,但表的结构、列、约束、索引等不会被删除
3.3.3 DROP
DROP DROP TABLE myorder; 删除表
DROP DATABASE myorder; 删除数据库
drop table mytab6; 放入回收站
show recyclebin; 查看回收站
purge recyclebin; 清空回收站
drop table test02 purge; 删除表并清空(彻底删除)
"闪回技术" 还原回收站
4 CREATE:数据库、表、视图、索引
4.1 登录
# 登录MySQL
$ mysql -u root -p123456
# 退出MySQL数据库服务器
exit;
4.2 数据类型
MySQL 支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
类型 | 大小 | 用途 Java类型
|------------- |----------------- -|----------------------------------------------
| TINYINT | 1 Bytes | 小整数值 java.lang.Integer
| SMALLINT | 2 Bytes | 大整数值 java.lang.Integer
| MEDIUMINT | 3 Bytes | 大整数值 java.lang.Integer
| INT或INTEGER | 4 Bytes | 大整数值 java.lang.Integer
| BIGINT | 8 Bytes | 极大整数值 java.math.BigInteger
| FLOAT | 4 Bytes | 单精度 java.lang.Float
| DOUBLE | 8 Bytes | 双精度 java.lang.Double
| DECIMAL | 对DECIMAL(M,D) | 小数值 java.math.BigDecimal
类型 | 大小 | 用途
|------------- |----------------- -|----------------------------------------------
| DATE | 3 Bytes | 日期值 java.sql.Date
| TIME | 3 Bytes | 时间值或持续时间 java.sql.Time
| YEAR | 1 Bytes | 年份值 java.sql.Date
| DATETIME | 8 Bytes | 混合日期和时间值 java.sql.Timestamp
| TIMESTAMP | 4 Bytes | 混合日期和时间值,时间戳 java.sql.Timestamp
类型 | 大小 | 用途
|------------|-----------------------|----------------------------------------------
| CHAR | 0-255 bytes | 定长字符串 java.lang.String
| VARCHAR | 0-65535 bytes | 变长字符串 java.lang.String
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 java.lang.byte[]
| TINYTEXT | 0-255 bytes | 短文本字符串 java.lang.String
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 java.lang.byte[]
| TEXT | 0-65 535 bytes | 长文本数据 java.lang.String
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 java.lang.byte[]
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 java.lang.String
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 java.lang.byte[]
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 java.lang.String
-------------------------------------------------------------------------------------------------------------
01.varchar与char的区别
a.char的特点
char表示定长字符串,长度是固定的;
如果插入数据的长度小于char的固定长度时,则用空格填充;
因为长度固定,所以存取速度要比varchar快很多,甚至能快50%,但正因为其长度固定,所以会占据多余的空间,是空间换时间的做法;
对于char来说,最多能存放的字符个数为255,和编码无关
b.varchar的特点
varchar表示可变长字符串,长度是可变的;
插入的数据是多长,就按照多长来存储;
varchar在存取方面与char相反,它存取慢,因为长度不固定,但正因如此,不占据多余的空间,是时间换空间的做法;
对于varchar来说,最多能存放的字符个数为65532
02.mysql中int(10)、char(10)、varchar(10)的区别
int(10)的10表示显示的数据的长度,不是存储数据的大小;chart(10)和varchar(10)的10表示存储数据的大小,即表示存储多少个字符。
char(10)表示存储定长的10个字符,不足10个就用空格补齐,占用更多的存储空间
varchar(10)表示存储10个变长的字符,存储多少个就是多少个,空格也按一个字符存储,这一点是和char(10)的空格不同的,char(10)的空格表示占位不算一个字符
4.3 数据库
CREATE 创建数据库、表、视图、索引
----------------------------------------------------------------------------------------
CREATE DATABASE database_name; 创建数据库
SHOW DATABASES; 显示所有数据库
USE database_name; 使用数据库
DROP DATABASE database_name; 删除数据库
4.4 表:CREATE
CREATE 创建数据库、表、视图、索引
----------------------------------------------------------------------------------------
CREATE TABLE table_name( CREATE TABLE Customers( 创建表
column_name1 data_type(size), 客户ID INT IDENTITY(1,1) NOT NULL,
column_name2 data_type(size), 姓名 VARCHAR(10) NULL,
column_name3 data_type(size), 地址 VARCHAR(50) NULL,
column_name4 data_type(size), 城市 VARCHAR(20) NULL,
column_name5 data_type(size), 邮编 CHAR(6) NULL,
.... 省份 VARCHAR(20) NULL
); );
SHOW TABLES; 显示数据库中的所有表
DESC pet; 查看数据表结构(describe pet)
DROP TABLE pet; 删除表
----------------------------------------------------------------------------------------
注意事项:
1.权限和空间问题
2.表名的规定:
a.必须以字母开头
b.表名只能包含: 大小写字母、数字、_、$、#
c.长度 1-30个字符
d.不能与数据库中其他对象重名(表,视图、索引、触发器、存储过程....)
e.不能与保留字重名
4.5 列:ALTER
ALTER 列:增、删、改
----------------------------------------------------------------------------------------
alter table mytab6 add myother varchar2(10) 增加新列
alter table mytab6 drop column myother2 删除列
alter table mytab6 rename column myother to myother3 重命名列 rename ... to ...
----------------------------------------------------------------------------------------
-- 修改列 modify
alter table mytab6 modify myother varchar2(20) 修改列的长度
alter table mytab6 modify myother number 修改列的类型
-- 注意:blob/clob不能修改 -> 先删除此列,重新追加
alter table mytab6 add myother2 blob
alter table mytab6 modify myother2 number
4.6 索引
CREATE 创建数据库、表、视图、索引
----------------------------------------------------------------------------------------
1.索引分类
主键索引:不能重复 id不能是null
唯一索引:不能重复 id可以是null
单值索引:单列age 一个表可以多个单值索引
复合索引:多个列构成的索引 相当于二级目录(name,age)、(a,b,c,d,...,n)
2.创建索引
方式一:create 索引类型 索引名 on 表(字段)
a.主键
create table tb(
id int(4) auto_increment,
name varchar(5),
dept varchar(5),
primary key(id)
)ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
b.单值
create index dept_index on tb(dept);
c.唯一
create unique index name_index on tb(name);
d.复合索引
create index dept_name_index on tb(dept,name);
方式二:alter table 表名 索引类型 索引名(字段)
a.主键
alter table tb add primary key(id);
b.单值
alter table tb add index dept_index(dept);
c.唯一
alter table tb add unique index name_index(name);
d.复合索引
alter table tb add index dept_name_index(dept,name);
注意:如果一个字段是primary key,则改字段默认就是“主键索引”
3.删除索引 drop index 索引名 on 表名 ;
drop index name_index on tb ;
4.查询索引 show index from 表名;
show index from 表名\G
4.7 视图
CREATE VIEW 视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。
但是,视图并不在数据库中以存储的数据值集形式存在。
----------------------------------------------------------------------------------------
CREATE VIEW view_name AS 创建视图
SELECT column_name(s)
FROM table_name
WHERE condition
ALTER VIEW view_name AS 更新视图
SELECT column_name(s)
FROM table_name
WHERE condition
SELECT * FROM view_name 查看视图
DROP VIEW view_name 删除视图
注释:视图总是显示最新数据!每当用户查询视图时,数据库引擎就使用视图的 SQL 语句重新构建数据
----------------------------------------------------------------------------------------
CREATE VIEW Customer_GD AS 创建一个只有广东省的视图
SELECT *
FROM Customers
WHERE 省份='广东省
ALTER VIEW Customer_GD AS 更新视图
SELECT *
FROM Customers
WHERE 省份='广东省 AND 客户ID=6
SELECT * FROM Customer_GD 查看视图
DROP VIEW Customer_GD 删除视图
-------------------------------------------------------------------------------------------------------------
01.为什么要使用视图?什么是视图?
为了提高复杂SQL语句的复用性和表操作的安全性,MySQL数据库管理系统提供了视图特性。所谓视图,本质上是一种虚拟表,在物理上是不存在的,其内容与真实的表相似,包含一系列带有名称的列和行数据。但是,视图并不在数据库中以储存的数据值形式存在。行和列数据来自定义视图的查询所引用基本表,并且在具体引用视图时动态生成。
视图使开发者只关心感兴趣的某些特定数据和所负责的特定任务,只能看到视图中所定义的数据,而不是视图所引用表中的数据,从而提高了数据库中数据的安全性。
02.视图的特点如下:
视图的列可以来自不同的表,是表的抽象和在逻辑意义上建立的新关系。
视图是由基本表(实表)产生的表(虚表)。
视图的建立和删除不影响基本表。
对视图内容的更新(添加,删除和修改)直接影响基本表。
当视图来自多个基本表时,不允许添加和删除数据。
视图的操作包括创建视图,查看视图,删除视图和修改视图。
03.下面是视图的常见使用场景:
重用SQL语句;
简化复杂的SQL操作。在编写查询后,可以方便的重用它而不必知道它的基本查询细节;
使用表的组成部分而不是整个表;
保护数据。可以给用户授予表的特定部分的访问权限而不是整个表的访问权限;
更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
04.视图的优点
查询简单化。视图能简化用户的操作
数据安全性。视图使用户能以多种角度看待同一数据,能够对机密数据提供安全保护
逻辑数据独立性。视图对重构数据库提供了一定程度的逻辑独立性
5 三个模型、三大范式、六大约束、六大索引类型
5.1 三个模型
概念模型 E-R图主要是由实体、属性和联系三个要素构成的。
逻辑模型 一个实体转换为一个关系;一个联系也转换为一个关系 1:1 1:n m:n
物理模型 针对上述逻辑模型所说的内容,在具体的物理介质上实现出来。如:数据库使用SQL Server 2000,编写具体的SQL脚本在数据库服务器上将数据库建立起来
5.2 三大范式
1NF 确保每列的原子性(不可再分)
2NF 除了主键以外的其他字段,都依赖于主键
3NF 除了主键以外的其他字段,都不传递依赖于主键
优点 三大范式可以帮助我们规范数据的设计,好处是防止数据混乱、数据冗余(重复)
缺点 很难严格排除出所有不满足的表,并且难以拆分:会一定程度影响性能
原则 要么满足第N范式,必须先满足第N-1范式。
x->拆?
a -> a+b+c
select ..a,b,c where 关联查询
多表查询会比单表查询更加消耗性能。
建议 三大范式 只是一个建议,不必严格遵守。
使用 实际使用时,需要“规范性”和“易用性、性能”间综合考虑
5.2.1 第1个NF
1NF 确保每列的原子性(不可再分)
-------------------------------------------------------------------------------------------------------------
-- student表
id name address
1 zs 陕西省西安市长安区
拆:
id name province city zone
5.2.2 第2个NF
2NF 除了主键以外的其他字段,都依赖于主键
-- 宏观:每张表只描述一件事情(例如,一个student表描述的全部是学生字段)
-- 微观:通过2NF定义:除了主键以外的其他字段,都依赖于主键
依赖于:A->B,
换种说法:“决定”的反义词, B->A
a,b,c,d,e
a决定b,
a决定c,
a决定d,
a决定e
5.2.3 第3个NF
微观:除了主键以外的其他字段,都不传递依赖于主键
A->B:“A决定了B” 或 “B决定于A”
X->Y->Z:“X传递决定了Z” 或 “Z传递依赖于X”
5.3 六大约束1
00.完整性约束:保证数据的正确性、相容性、防止数据冗余等。
域完整性: 列 数据类型、非空约束、检查约束、外键约束
实体完整性: 行 主键约束、唯一约束
引用完整性: 不同表之间 外键约束
自定义完整性:触发器(当执行换一个操作时,会自动触发另一个操作)。例如:自定义需求,学生的上学时间 必须在出生日期之后。
01.为什么要尽量设定一个主键?
主键是数据库确保数据行在整张表唯一性的保障,即使业务上本张表没有主键,也建议添加一个自增长的ID列作为主键。设定了主键之后,在后续的删改查的时候可能更加快速以及确保操作数据范围安全。
02.主键使用自增ID还是UUID?
推荐使用自增ID,不要使用UUID。
因为在InnoDB存储引擎中,主键索引是作为聚簇索引存在的,也就是说,主键索引的B+树叶子节点上存储了主键索引以及全部的数据(按照顺序),如果主键索引是自增ID,那么只需要不断向后排列即可,如果是UUID,由于到来的ID与原来的大小不确定,会造成非常多的数据插入,数据移动,然后导致产生很多的内存碎片,进而造成插入性能的下降。
03.超键、候选键、主键、外键分别是什么?
超键:在关系中能唯一标识元组的属性集称为关系模式的超键。一个属性可以为作为一个超键,多个属性组合在一起也可以作为一个超键。超键包含候选键和主键。
候选键:最小超键,即没有冗余元素的超键。
主键:数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合。一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null)。
外键:在一个表中存在的另一个表的主键称此表的外键。
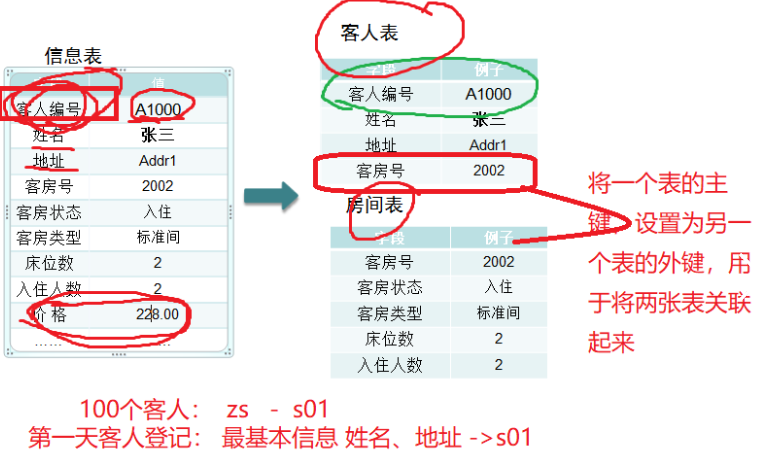
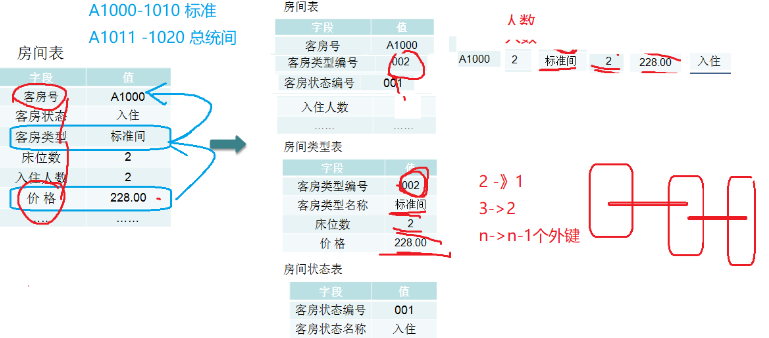
04.主键约束和唯一约束的区别:
a.【主键不能为Null】,【唯一可以为null】
b.主键可以是复合主键,也可以是单值主键(id)
c.一张表中只能设置一次主键(复合主键),但唯一键可以设置多次
05.外键使用建议
1.当父表中没有相对应数据时,不要向子表增加数据(如果sub表没有编号为2的课程,那么子表student不要去选择2号课程)
2.不要更改父表的数据,导致子表孤立
3.建议:在创建外键时直接设置成级联删除或级联置空
4.删除表?先删除子表,再删除父表
5.3.1 追加约束
-- 无约束的表
create table student4(
stuno number(3) ,
stuname varchar2(10) ,
stuaddress varchar2(20) ,
subid number(3)
);
alter table 表名 add constraint 约束类型_字段名 约束类型(约束名)
alter table student4 add constraint UQ_stuaddress4 unique(stuaddress);
alter table student4 add constraint PK_stuno4 primary key(stuno);
alter table student4 add constraint CK_stuname4 check(length(stuname)>2);
alter table student4 add constraint FK_student4_sub foreign key(subid) references sub(sid);
-------------------------------------------------------------------------------------------------------------
-- alter table add 不适用于非空
alter table student4 add constraint NN_stuname not null(stuname);
ORA-00904: : 标识符无效
-- alter table 表名 motidy 字段名 constraint 约束类型_字段名 约束类型
alter table student4 modify stuname constraint NN_stuname4 not null ;
-------------------------------------------------------------------------------------------------------------
-- alter table add 不适用于默认
alter table student4 add constraint DF_stuname default 'hello';
ORA-00904: : 标识符无效
-- alter table 表名 motidy 字段名 约束类型(默认名)
alter table student4 modify stuname default '默认名字';
5.3.2 删除约束
-- alter table 表名 drop constraint 约束类型_字段名;
alter table student4 drop constraint UQ_stuaddress4;
alter table student4 drop constraint PK_stuno4;
alter table student4 drop constraint CK_stuname4;
alter table student4 drop constraint FK_student4_sub;
alter table student4 drop constraint NN_stuname4;
-- 特殊情况: 默认约束(删除默认约束:将默认约束置为null)
alter table student4 modify stuname default null;
5.4 六大约束2
约束 约束是作用于数据表中列上的规则,用于限制表中数据的类型。约束的存在保证了数据库中数据的精确性和可靠性。
约束有列级和表级之分,列级约束作用于单一的列,而表级约束作用于整张数据表。
----------------------------------------------------------------------------------------
约束类型 约束描述 约束命名
主键约束(Primary key) 唯一标识数据表中的行/记录 PK_stuno
外键约束(Foreign Key) 唯一标识其他表中的一条行/记录 FK_子表_父表
非空约束(Not nu11) 保证列中数据不能有 NULL 值 NN_字段名
默认约束(Default) 提供该列数据未指定时所采用的默认值 一般不需要命名
唯一约束(Unique) 保证列中的所有数据各不相同 UQ_字段名
检查约束(Check) 此约束保证列中的所有值满足某一条件 CK_字段名
5.4.1 主键约束(Primary key)
CREATE TABLE employees ( --添加(主键)
id INT PRIMARY KEY,
name VARCHAR(50),
age INT
);
CREATE TABLE user ( --添加(复合主键)
id INT,
name VARCHAR(50),
age INT,
PRIMARY KEY(id, name)
);
CREATE TABLE employees ( --添加(主键+自增约束)
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
age INT
);
CREATE TABLE sys_menu --添加(使用CONSTRAINT关键字、约束名称)
(
id INT(64) AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
CONSTRAINT pk_sys_menu PRIMARY KEY (id)
);
ALTER TABLE employees ADD PRIMARY KEY (id); --添加
ALTER TABLE employees MODIFY COLUMN id INT PRIMARY KEY; --添加
ALTER TABLE employees DROP PRIMARY KEY; --删除
5.4.2 外键约束(Foreign Key)
CREATE TABLE orders ( --添加
order_id INT,
product_id INT,
customer_id INT,
FOREIGN KEY (product_id) REFERENCES products(id),
FOREIGN KEY (customer_id) REFERENCES customers(id)
);
CREATE TABLE orders --添加(使用CONSTRAINT关键字、约束名称)
(
order_id INT,
product_id INT,
customer_id INT,
CONSTRAINT fk_product FOREIGN KEY (product_id) REFERENCES products(id),
CONSTRAINT fk_customer FOREIGN KEY (customer_id) REFERENCES customers(id)
);
ALTER TABLE orders ADD FOREIGN KEY (product_id) REFERENCES products(id); --添加
ALTER TABLE orders ADD FOREIGN KEY (customer_id) REFERENCES customers(id);
ALTER TABLE orders MODIFY COLUMN product_id INT, ADD FOREIGN KEY (product_id) REFERENCES products(id); --添加
ALTER TABLE orders MODIFY COLUMN customer_id INT, ADD FOREIGN KEY (customer_id) REFERENCES customers(id);
ALTER TABLE orders DROP FOREIGN KEY fk_product_id, --删除
ALTER TABLE orders DROP FOREIGN KEY fk_customer_id;
5.4.3 非空约束(Not nu11)
CREATE TABLE products ( --添加
id INT,
name VARCHAR(50) NOT NULL,
price DECIMAL(10, 2)
);
CREATE TABLE products --添加(使用CONSTRAINT关键字、约束名称)
(
id INT,
name VARCHAR(50),
price DECIMAL(10, 2),
CONSTRAINT nn_products_name NOT NULL (name)
);
ALTER TABLE products ADD CONSTRAINT products_name_nn NOT NULL (name); --添加
ALTER TABLE products MODIFY COLUMN name VARCHAR(50) NOT NULL; --添加
ALTER TABLE products MODIFY COLUMN name VARCHAR(50) NULL; --删除
5.4.4 默认约束(Default)
CREATE TABLE customers ( --添加
id INT,
name VARCHAR(50),
email VARCHAR(50) DEFAULT 'N/A'
);
CREATE TABLE customers --添加(使用CONSTRAINT关键字、约束名称)
(
id INT,
name VARCHAR(50),
email VARCHAR(50) DEFAULT 'N/A',
CONSTRAINT default_customers_email DEFAULT 'N/A' FOR email
);
ALTER TABLE customers ALTER COLUMN email SET DEFAULT 'N/A'; --添加
ALTER TABLE customers MODIFY COLUMN email VARCHAR(50) DEFAULT 'N/A'; --添加
ALTER TABLE customers ALTER COLUMN email DROP DEFAULT; --删除
5.4.5 唯一约束(Unique)
CREATE TABLE employees ( --添加
id INT,
email VARCHAR(50) UNIQUE,
name VARCHAR(50)
);
CREATE TABLE employees --添加(使用CONSTRAINT关键字、约束名称)
(
id INT,
email VARCHAR(50),
CONSTRAINT uk_email UNIQUE (email)
);
ALTER TABLE employees ADD UNIQUE (email); --添加
ALTER TABLE employees MODIFY COLUMN email VARCHAR(50), ADD UNIQUE (email); --添加
ALTER TABLE employees DROP INDEX email; --删除
5.4.6 检查约束(Check)
CREATE TABLE employees --添加(使用CONSTRAINT关键字、约束名称)
(
id INT,
age INT,
CONSTRAINT ck_age CHECK (age >= 18 AND age <= 65)
);
ALTER TABLE employees ADD CHECK (age >= 18 AND age <= 65); --添加
ALTER TABLE employees MODIFY COLUMN age INT, ADD CHECK (age >= 18 AND age <= 65); --添加
ALTER TABLE employees DROP CHECK check_age; --删除
5.5 外键删除
如果删除父表中外键所指向的列,2个策略:级联删除(on delete cascade)|级联置空(on delete set null)
ON DELETE操作
restrict(约束): 当在父表(即外键的来源表)中删除对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除。
no action: 意思同restrict.即如果存在从数据,不允许删除主数据。
cascade(级联): 当在父表(即外键的来源表)中删除对应记录时,首先检查该记录是否有对应外键,如果有则也删除外键在子表(即包含外键的表)中的记录。
set null: 当在父表(即外键的来源表)中删除对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(不过这就要求该外键允许取null)。
ON UPDATE操作
restrict(约束): 当在父表(即外键的来源表)中更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许更新。
no action: 意思同restrict.
cascade(级联): 当在父表(即外键的来源表)中更新对应记录时,首先检查该记录是否有对应外键,如果有则也更新外键在子表(即包含外键的表)中的记录。
set null: 当在父表(即外键的来源表)中更新对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(不过这就要求该外键允许取null)。
5.5.1 级联删除:on delete cascade
-- 级联删除:当删除父表中的数据时,子表会跟着删除相对应的数据;
-- 先创建父表sub
create table sub(
sid number(3) unique,
sname varchar2(10)
);
insert into sub values(1,'java');
insert into sub values(2,'python');
-- 再创建子表student3,同时设置外键+级联删除
create table student3(
stuno number(3) ,
stuname varchar2(10) ,
stuaddress varchar2(20) ,
subid number(3) ,
constraint FK_student3_sub foreign key(subid) references sub(sid) on delete cascade
);
insert into student3(stuno,stuname,subid) values(1,'zs',1);
insert into student3(stuno,stuname,subid) values(2,'ls',1);
insert into student3(stuno,stuname,subid) values(3,'ww',2);
-- 子表存在subid=2数据的前提下,删除父表sid=2数据
SQL> delete from sub where sid=2;
已删除 1 行。
-- 级联删除后两表数据
SQL> select * from student3;
STUNO STUNAME STUADDRESS SUBID
---------- -------------------- ---------------------------------------- ----------
1 zs 1
2 ls 1
SQL> select * from sub;
SID SNAME
---------- --------------------
1 java
5.5.2 级联置空:on delete set null
-- 级联置空:当删除父表中的数据时,子表会将相对应的那一字段的值设置为Null,其他字段不影响;
-- 先创建父表sub
create table sub(
sid number(3) unique,
sname varchar2(10)
);
insert into sub values(1,'java');
insert into sub values(2,'python');
-- 再创建子表student3,同时设置外键+级联删除
create table student3(
stuno number(3) ,
stuname varchar2(10) ,
stuaddress varchar2(20) ,
subid number(3) ,
constraint FK_student3_sub foreign key(subid) references sub(sid) on delete set null
);
insert into student3(stuno,stuname,subid) values(1,'zs',1);
insert into student3(stuno,stuname,subid) values(2,'ls',1);
insert into student3(stuno,stuname,subid) values(3,'ww',2);
-- 子表存在subid=2数据的前提下,删除父表sid=2数据
SQL> delete from sub where sid='2';
已删除 1 行。
-- 级联删除后两表数据
SQL> select * from student3;
STUNO STUNAME STUADDRESS SUBID
---------- -------------------- ---------------------------------------- ----------
1 zs 1
2 ls 1
3 ww
SQL> select * from sub;
SID SNAME
---------- --------------------
1 java
5.6 六大索引类型
00.总结
a.总结
约束更多地是对数据行为的限制,而索引主要是优化查询性能。两者可以结合使用,但应用场景不同。
b.约束与索引的联系
唯一约束会自动创建唯一索引。
主键约束会自动创建主键索引。
约束主要是为了数据完整性,而索引是为了查询效率。
c.索引类型的区别
普通索引与复合索引:复合索引适合多列条件查询,而普通索引只针对单列。
唯一索引和普通索引:唯一索引会检查值的唯一性,而普通索引不限制。
主键索引和唯一索引:主键索引是表的唯一标识,不能包含 NULL,唯一索引可以包含。
全文索引和空间索引:全文索引适用于文本搜索,空间索引用于地理数据。
d.索引使用
sys_depart uniq_depart_org_code org_code UNIQUE BTREE 必须设置
sys_depart idx_sd_parent_id parent_id NORMAL BTREE 必须设置
sys_depart idx_sd_depart_order depart_order NORMAL BTREE 必须设置
sys_depart idx_sd_org_code org_code NORMAL BTREE 必须设置
-----------------------------------------------------------------------------------------------------
在数据库中,如果在同一个字段上既定义了 UNIQUE 索引又定义了 NORMAL(普通)索引,它们实际上不会直接冲突,但可能会引发不必要的资源消耗和混淆。
详细解释
1.UNIQUE 索引的作用
UNIQUE 索引会强制字段的值具有唯一性,数据库会对该字段的值进行唯一性检查。
UNIQUE 索引本身也可以用来提高查询性能,因为它也是一种索引。
2.NORMAL(普通)索引的作用
NORMAL 索引没有唯一性限制,它只是为了提高查询速度。
多余的普通索引可能会在插入、更新或删除数据时增加索引维护的成本。
3.为什么可能会冲突?
索引冗余:在一个字段上同时有 UNIQUE 索引和 NORMAL 索引,会导致两个索引都需要维护,但实际上 UNIQUE 索引已经包含了 NORMAL 索引的功能。UNIQUE 索引不仅提供了查询加速,还提供了唯一性约束。
混淆维护:多个索引可能让开发人员或数据库管理员在优化查询时感到困惑,不清楚应该利用哪个索引。
性能问题:虽然不会直接冲突,但多余的索引会增加磁盘空间占用,并在写操作(如插入、更新、删除)时增加索引更新的开销。
4.解决方案
在字段上,通常不需要同时存在 UNIQUE 和 NORMAL 索引。如果你的需求是确保字段唯一性,并且需要加速查询:
保留 UNIQUE 索引:它同时提供唯一性约束和查询加速。
删除 NORMAL 索引:普通索引是多余的,因为 UNIQUE 索引已经涵盖了查询优化。
01.MySQL 六大约束,MySQL 的约束是为了确保数据库数据的完整性和一致性。以下是六大约束及其功能:
a.NOT NULL(非空约束)
保证字段值不能为 NULL,即要求字段必须有值。
示例:name VARCHAR(50) NOT NULL
b.UNIQUE(唯一约束)
保证字段的值在该列中唯一,不能重复,但可以有 NULL 值(NULL 被认为是唯一的)。
示例:email VARCHAR(100) UNIQUE
c.PRIMARY KEY(主键约束)
主键是表中的唯一标识,要求字段值唯一且不能为 NULL。
一张表只能有一个主键。
示例:id INT PRIMARY KEY
d.FOREIGN KEY(外键约束)
用于建立表与表之间的关联关系,外键字段的值必须与主表对应字段的值匹配。
示例:FOREIGN KEY (order_id) REFERENCES orders(id)
e.CHECK(检查约束)
检查字段值是否符合某些条件,MySQL 8.0 及以上版本支持。
示例:age INT CHECK (age >= 18)
f.DEFAULT(默认值约束)
为字段设置一个默认值,如果插入数据时未指定值,则使用默认值。
示例:status VARCHAR(20) DEFAULT 'active'
02.MySQL 六种索引类型,索引是为加速查询而设置的数据结构,它们提高了数据访问速度,但会增加插入和更新操作的成本。以下是 MySQL 中的六种常见索引类型:
a.普通索引(Index)
最常用的索引类型,用于加速查询,没有特殊的约束。
示例:CREATE INDEX idx_name ON users(name);
b.唯一索引(Unique Index)
确保索引列中的值是唯一的,类似于 UNIQUE 约束。
示例:CREATE UNIQUE INDEX idx_email ON users(email);
c.主键索引(Primary Key Index)
主键自动创建一个唯一索引,值必须唯一且非空。
示例:PRIMARY KEY (id)
d.复合索引(Composite Index 或 Multi-Column Index)
在多个列上创建的索引,用于优化多列条件的查询。
示例:CREATE INDEX idx_name_age ON users(name, age);
e.全文索引(Full-Text Index)
用于全文搜索,支持 MATCH 和 AGAINST 操作。适合处理大文本数据(如文章或评论)。
示例:CREATE FULLTEXT INDEX idx_content ON articles(content);
f.空间索引(Spatial Index)
用于存储和查询地理数据,适用于 GIS(地理信息系统)。
必须基于 MyISAM 表或 InnoDB 的 SPATIAL 列类型。
示例:CREATE SPATIAL INDEX idx_location ON geo_data(location);
6 事务:Transaction
6.1 概念
01.概念
事务:事务是由一组操作构成的可靠的独立的工作单元,事务具备ACID的特性,即原子性、一致性、隔离性和持久性。
本地事务:当事务由资源管理器本地管理时被称作本地事务。本地事务的优点就是支持严格的ACID特性,高效,可靠,状态可以只在资源管理器中维护,而且应用编程模型简单。但是本地事务不具备分布式事务的处理能力,隔离的最小单位受限于资源管理器。
全局事务:当事务由全局事务管理器进行全局管理时成为全局事务,事务管理器负责管理全局的事务状态和参与的资源,协同资源的一致提交回滚。
02.本地事务:
①内容:一个事务对应一个数据库连接,凡是不符合上述1:1关系的,都不能使用本地事务
②以下情景都无法使用本地事务:
场景一:单节点中存在多个数据库实例
例如在本地建立了两个数据库:订单数据库、支付数据库
下单操作=订单数据库+支付数据库
场景二:分布式系统中,部署在不同节点上的多个服务访问同一个数据库
---------------------------------------------------------------------------------------------------------
以上两个场景说明:本地事务的使用性十分有限,因此需要使用分布式事务
假设使用本地事务处理分布式数据库
下单操作=订单数据+支付数据
服务器A=下单操作、订单数据库
服务器B=支付数据库
03.事务可以嵌套吗?
可以,因为嵌套事务也是众多事务分类中的一种,它是一个层次结构框架。
有一个顶层事务控制着各个层次的事务,顶层事务之下嵌套的事务被称为子事务,它控制每一个局部的变换。
需要注意的是,MySQL数据库不支持嵌套事务。
04.分布式事务与分布式锁的区别:
分布式锁解决的是分布式资源抢占的问题;分布式事务和本地事务是解决流程化提交问题。
6.2 保存点
01.描述
打游戏:10关 1 ,2(savepoint), 3,4,5 (savepoint), 6,7,8 -->rollback
语法:savepoint 保存点名字
02.操作
insert into xx values(1,'zs'); --事务开始
insert into xx values(2,'ls');
savepoint initdate ; --保存点“类似存档”
insert into xx values(3,'ww');
rollback to savepoint initdate; --返回保存点
6.3 生命周期
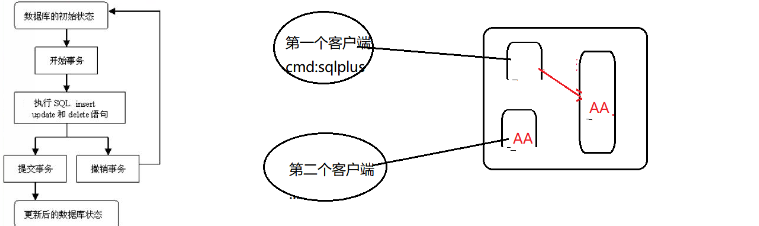
01.提交方式
MySQL:自动提交,自动将每一条DML语句直接commit
Oracle:手工提交
02.事务的过程
事务的开始标识:第一条DML
事务的中间过程:各种DML操作
事务的结束:a.提交
i.显示提交:commit
ii.隐式提交(自动提交):正常退出exit(ctrl+c)、DCL(grant ....to..., revoke ..from )、DDL(create ... ,drop ....)
b.回滚
i.显示回滚:rollback
ii.隐式回滚:异常退出(宕机、断电)
6.4 四个特征ACID
01.概念
事务:作为单个逻辑工作单元执行的一系列操作
事务(Transaction)是操作数据库中某个数据项的一个程序执行单元(unit)
事务是一个不可分割的数据库操作序列,也是数据库并发控制的基本单位,其执行的结果必须使数据库从一种一致性状态变到另一种一致性状态。事务是逻辑上的一组操作,要么都执行,要么都不执行。
02.事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
1、Atomic原子性 要么都成功,要么都失败 借钱zs -1000 ls +1000
2、Consistency一致性 事务执行前后,总量保持一致 人类的全部财富值
3、Isolation隔离性 各个事务并发执行时,彼此独立
4、Durab111ty特久性 持久化操作
1、Atomic原子性
事务必须是一个原子的操作序列单元,事务中包含的各项操作在一次执行过程中,要么全部执行成功,要么全部不执行,任何一项失败,整个事务回滚,只有全部都执行成功,整个事务才算成功。
2、Consistency一致性
事务的执行不能破坏数据库数据的完整性和一致性,事务在执行之前和之后,数据库都必须处于一致性状态。
3、Isolation隔离性
在并发环境中,并发的事务是相互隔离的,一个事务的执行不能被其他事务干扰。即不同的事务并发操纵相同的数据时,每个事务都有各自完整的数据空间,即一个事务内部的操作及使用的数据对其他并发事务是隔离的,并发执行的各个事务之间不能相互干扰。
4、Durability持久性
持久性(durability):持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中对应数据的状态变更就应该是永久性的。
即使发生系统崩溃或机器宕机,只要数据库能够重新启动,那么一定能够将其恢复到事务成功结束时的状态。
6.5 四个事务隔离级别
01.SQL中的4个事务隔离级别
(1)未提交读(READ UNCOMMITTED):所有事务都可以看到其他事务未提交的修改。一般很少使用;
(2)提交读(READ COMMITTED):Oracle默认隔离级别,事务之间只能看到彼此已提交的变更修改;
(3)可重复读(REPEATABLE READ):MySQL默认隔离级别,同一事务中的多次查询会看到相同的数据行;可以解决不可重复读,但可能出现幻读;
(4)可串行化(SERIALIZABLE):最高的隔离级别,事务串行的执行,前一个事务执行完,后面的事务会执行。读取每条数据都会加锁,会导致大量的超时和锁争用问题;
02.SQL中的4个事务隔离级别
(1)读未提交:允许脏读。如果一个事务正在处理某一数据,并对其进行了更新,但同时尚未完成事务,因此事务没有提交,与此同时,允许另一个事务也能够访问该数据。例如A将变量n从0累加到10才提交事务,此时B可能读到n变量从0到10之间的所有中间值。
(2)读已提交:允许不可重复读。只允许读到已经提交的数据。即事务A在将n从0累加到10的过程中,B无法看到n的中间值,之中只能看到10。同时有事务C进行从10到20的累加,此时B在同一个事务内再次读时,读到的是20。
(3)可重复读:允许幻读。保证在事务处理过程中,多次读取同一个数据时,其值都和事务开始时刻时是一致的。禁止脏读、不可重复读。幻读即同样的事务操作,在前后两个时间段内执行对同一个数据项的读取,可能出现不一致的结果。保证B在同一个事务内,多次读取n的值,读到的都是初始值0。幻读,就是不同事务,读到的n的数据可能是0,可能10,可能是20
(4)串行化:最严格的事务,要求所有事务被串行执行,不能并发执行。
03.如果不对事务进行并发控制,我们看看数据库并发操作是会有那些异常情形
(1)一类丢失更新:两个事物读同一数据,一个修改字段1,一个修改字段2,后提交的恢复了先提交修改的字段。
(2)二类丢失更新:两个事物读同一数据,都修改同一字段,后提交的覆盖了先提交的修改。
(3)脏读:读到了未提交的值,万一该事物回滚,则产生脏读。
(4)不可重复读:两个查询之间,被另外一个事务修改了数据的内容,产生内容的不一致。
(5)幻读:两个查询之间,被另外一个事务插入或删除了记录,产生结果集的不一致。

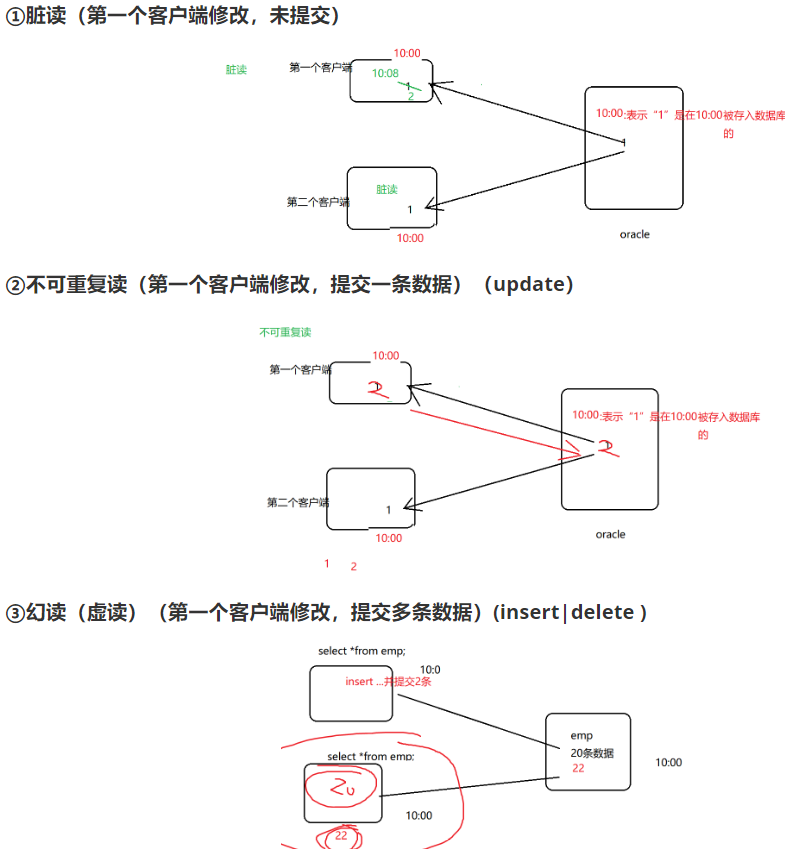
6.6 脏读、幻读、不可重复读
00.在多个事务【并发操作】时,数据库中会出现下面三种问题:脏读,幻读,不可重复读。
01.脏读(Dirty Read)
事务A读到了事务B还未提交的数据:
事务A读取的数据,事务B对该数据进行修改还未提交数据之前,事务A再次读取数据会读到事务B已经修改后的数据,
如果此时事务B进行回滚或再次修改该数据然后提交,事务A读到的数据就是脏数据,这个情况被称为脏读(Dirty Read)。
---------------------------------------------------------------------------------------------------------
当一个事务正在访问数据,并对此数据进行了修改(1->2),但是这种修改【还没有提交到数据库(commit)】;
此时,另一个事务也在访问这个数据。本质:某个事务(客户端)读取到的数据是过时的。
02.幻读(Phantom Read)
事务A进行范围查询时,事务B中新增了满足该范围条件的记录,当事务A再次按该条件进行范围查询,
会查到在事务B中提交的新的满足条件的记录(幻行 Phantom Row)。
在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,
而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
---------------------------------------------------------------------------------------------------------
在一个事务内(客户端)内,多次读取同一批数据,但结果不同。
03.不可重复读(Unrepeatable Read)
事务A在读取某些数据后,再次读取该数据,发现读出的该数据已经在事务B中发生了变更或删除。
在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
---------------------------------------------------------------------------------------------------------
在一个事务内(客户端)内,多次读取同一个数据,但结果不同。
本质:就是事务A拿到了被其他事务B修改并提交后的数据
-------------------------------------------------------------------------------------------------------------
01.幻读和不可重复度的区别
幻读:在同一事务中,相同条件下,两次查询出来的 记录数 不一样
不可重复读:在同一事务中,相同条件下,两次查询出来的 数据 不一样
---------------------------------------------------------------------------------------------------------
不可重复读:对于“同一条”数据的查询操作 a -> b
幻读:对于“多条数据”的查询操作,数据量数 20条 -> 18条/22条
---------------------------------------------------------------------------------------------------------
不可重复读:update
幻读:insert/delete
02.如何解决幻读问题?
MySQL的InnoDB引擎,在默认的REPEATABLE READ的隔离级别下,实现了可重复读,同时也解决了幻读问题。
它使用Next-Key Lock算法实现了行锁,并且不允许读取已提交的数据,所以解决了不可重复读的问题。
另外,该算法包含了间隙锁,会锁定一个范围,因此也解决了幻读的问题。
7 事务:Transaction
在 MySQL 中,事务其实是一个最小的不可分割的工作单元。事务能够保证一个业务的完整性。
比如我们的银行转账:
-- a -> -100
UPDATE user set money = money - 100 WHERE name = 'a';
-- b -> +100
UPDATE user set money = money + 100 WHERE name = 'b';在实际项目中,假设只有一条 SQL 语句执行成功,而另外一条执行失败了,就会出现数据前后不一致。
因此,在执行多条有关联 SQL 语句时,事务可能会要求这些 SQL 语句要么同时执行成功,要么就都执行失败。
7.1 如何控制事务 - COMMIT / ROLLBACK
在 MySQL 中,事务的自动提交状态默认是开启的。
-- 查询事务的自动提交状态
SELECT @@AUTOCOMMIT;
+--------------+
| @@AUTOCOMMIT |
+--------------+
| 1 |
+--------------+自动提交的作用:当我们执行一条 SQL 语句的时候,其产生的效果就会立即体现出来,且不能回滚。
什么是回滚?举个例子:
CREATE DATABASE bank;
USE bank;
CREATE TABLE user (
id INT PRIMARY KEY,
name VARCHAR(20),
money INT
);
INSERT INTO user VALUES (1, 'a', 1000);
SELECT * FROM user;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 1000 |
+----+------+-------+可以看到,在执行插入语句后数据立刻生效,原因是 MySQL 中的事务自动将它提交到了数据库中。那么所谓回滚的意思就是,撤销执行过的所有 SQL 语句,使其回滚到最后一次提交数据时的状态。
在 MySQL 中使用 ROLLBACK 执行回滚:
-- 回滚到最后一次提交
ROLLBACK;
SELECT * FROM user;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 1000 |
+----+------+-------+由于所有执行过的 SQL 语句都已经被提交过了,所以数据并没有发生回滚。那如何让数据可以发生回滚?
-- 关闭自动提交
SET AUTOCOMMIT = 0;
-- 查询自动提交状态
SELECT @@AUTOCOMMIT;
+--------------+
| @@AUTOCOMMIT |
+--------------+
| 0 |
+--------------+将自动提交关闭后,测试数据回滚:
INSERT INTO user VALUES (2, 'b', 1000);
-- 关闭 AUTOCOMMIT 后,数据的变化是在一张虚拟的临时数据表中展示,
-- 发生变化的数据并没有真正插入到数据表中。
SELECT * FROM user;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 1000 |
| 2 | b | 1000 |
+----+------+-------+
-- 数据表中的真实数据其实还是:
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 1000 |
+----+------+-------+
-- 由于数据还没有真正提交,可以使用回滚
ROLLBACK;
-- 再次查询
SELECT * FROM user;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 1000 |
+----+------+-------+那如何将虚拟的数据真正提交到数据库中?使用 COMMIT :
INSERT INTO user VALUES (2, 'b', 1000);
-- 手动提交数据(持久性),
-- 将数据真正提交到数据库中,执行后不能再回滚提交过的数据。
COMMIT;
-- 提交后测试回滚
ROLLBACK;
-- 再次查询(回滚无效了)
SELECT * FROM user;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 1000 |
| 2 | b | 1000 |
+----+------+-------+总结
- 自动提交
查看自动提交状态:
SELECT @@AUTOCOMMIT;设置自动提交状态:
SET AUTOCOMMIT = 0。
- 手动提交
@@AUTOCOMMIT = 0时,使用COMMIT命令提交事务。
- 事务回滚
@@AUTOCOMMIT = 0时,使用ROLLBACK命令回滚事务。
事务的实际应用,让我们再回到银行转账项目:
-- 转账
UPDATE user set money = money - 100 WHERE name = 'a';
-- 到账
UPDATE user set money = money + 100 WHERE name = 'b';
SELECT * FROM user;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 900 |
| 2 | b | 1100 |
+----+------+-------+这时假设在转账时发生了意外,就可以使用 ROLLBACK 回滚到最后一次提交的状态:
-- 假设转账发生了意外,需要回滚。
ROLLBACK;
SELECT * FROM user;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 1000 |
| 2 | b | 1000 |
+----+------+-------+这时我们又回到了发生意外之前的状态,也就是说,事务给我们提供了一个可以反悔的机会。假设数据没有发生意外,这时可以手动将数据真正提交到数据表中:COMMIT 。
7.2 手动开启事务 - BEGIN / START TRANSACTION
事务的默认提交被开启 ( @@AUTOCOMMIT = 1 ) 后,此时就不能使用事务回滚了。但是我们还可以手动开启一个事务处理事件,使其可以发生回滚:
-- 使用 BEGIN 或者 START TRANSACTION 手动开启一个事务
-- START TRANSACTION;
BEGIN;
UPDATE user set money = money - 100 WHERE name = 'a';
UPDATE user set money = money + 100 WHERE name = 'b';
-- 由于手动开启的事务没有开启自动提交,
-- 此时发生变化的数据仍然是被保存在一张临时表中。
SELECT * FROM user;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 900 |
| 2 | b | 1100 |
+----+------+-------+
-- 测试回滚
ROLLBACK;
SELECT * FROM user;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 1000 |
| 2 | b | 1000 |
+----+------+-------+仍然使用 COMMIT 提交数据,提交后无法再发生本次事务的回滚。
BEGIN;
UPDATE user set money = money - 100 WHERE name = 'a';
UPDATE user set money = money + 100 WHERE name = 'b';
SELECT * FROM user;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 900 |
| 2 | b | 1100 |
+----+------+-------+
-- 提交数据
COMMIT;
-- 测试回滚(无效,因为表的数据已经被提交)
ROLLBACK;
mysql> SELECT * FROM user;
+----+------+-------+
| id | name | money |
+----+------+-------+
| 1 | a | 900 |
| 2 | b | 1100 |
+----+------+-------+7.3 事务的 ACID 特征与使用
事务的四大特征:
- A 原子性:事务是最小的单位,不可以再分割;
- C 一致性:要求同一事务中的 SQL 语句,必须保证同时成功或者失败;
- I 隔离性:事务1 和 事务2 之间是具有隔离性的;
- D 持久性:事务一旦结束 (
COMMIT) ,就不可以再返回了 (ROLLBACK) 。
7.4 事务的隔离性
事务的隔离性可分为四种 ( 性能从低到高 ) :
-
READ UNCOMMITTED ( 读取未提交 )
如果有多个事务,那么任意事务都可以看见其他事务的未提交数据。
-
READ COMMITTED ( 读取已提交 )
只能读取到其他事务已经提交的数据。
-
REPEATABLE READ ( 可被重复读 )
如果有多个连接都开启了事务,那么事务之间不能共享数据记录,否则只能共享已提交的记录。
-
SERIALIZABLE ( 串行化 )
所有的事务都会按照固定顺序执行,执行完一个事务后再继续执行下一个事务的写入操作。
查看当前数据库的默认隔离级别:
-- MySQL 8.x, GLOBAL 表示系统级别,不加表示会话级别。
SELECT @@GLOBAL.TRANSACTION_ISOLATION;
SELECT @@TRANSACTION_ISOLATION;
+--------------------------------+
| @@GLOBAL.TRANSACTION_ISOLATION |
+--------------------------------+
| REPEATABLE-READ | -- MySQL的默认隔离级别,可以重复读。
+--------------------------------+
-- MySQL 5.x
SELECT @@GLOBAL.TX_ISOLATION;
SELECT @@TX_ISOLATION;修改隔离级别:
-- 设置系统隔离级别,LEVEL 后面表示要设置的隔离级别 (READ UNCOMMITTED)。
SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
-- 查询系统隔离级别,发现已经被修改。
SELECT @@GLOBAL.TRANSACTION_ISOLATION;
+--------------------------------+
| @@GLOBAL.TRANSACTION_ISOLATION |
+--------------------------------+
| READ-UNCOMMITTED |
+--------------------------------+7.4.1 脏读
测试 READ UNCOMMITTED ( 读取未提交 ) 的隔离性:
INSERT INTO user VALUES (3, '小明', 1000);
INSERT INTO user VALUES (4, '淘宝店', 1000);
SELECT * FROM user;
+----+-----------+-------+
| id | name | money |
+----+-----------+-------+
| 1 | a | 900 |
| 2 | b | 1100 |
| 3 | 小明 | 1000 |
| 4 | 淘宝店 | 1000 |
+----+-----------+-------+
-- 开启一个事务操作数据
-- 假设小明在淘宝店买了一双800块钱的鞋子:
START TRANSACTION;
UPDATE user SET money = money - 800 WHERE name = '小明';
UPDATE user SET money = money + 800 WHERE name = '淘宝店';
-- 然后淘宝店在另一方查询结果,发现钱已到账。
SELECT * FROM user;
+----+-----------+-------+
| id | name | money |
+----+-----------+-------+
| 1 | a | 900 |
| 2 | b | 1100 |
| 3 | 小明 | 200 |
| 4 | 淘宝店 | 1800 |
+----+-----------+-------+由于小明的转账是在新开启的事务上进行操作的,而该操作的结果是可以被其他事务(另一方的淘宝店)看见的,因此淘宝店的查询结果是正确的,淘宝店确认到账。但就在这时,如果小明在它所处的事务上又执行了 ROLLBACK 命令,会发生什么?
-- 小明所处的事务
ROLLBACK;
-- 此时无论对方是谁,如果再去查询结果就会发现:
SELECT * FROM user;
+----+-----------+-------+
| id | name | money |
+----+-----------+-------+
| 1 | a | 900 |
| 2 | b | 1100 |
| 3 | 小明 | 1000 |
| 4 | 淘宝店 | 1000 |
+----+-----------+-------+这就是所谓的脏读,一个事务读取到另外一个事务还未提交的数据。这在实际开发中是不允许出现的。
7.4.2 读取已提交
把隔离级别设置为 READ COMMITTED :
SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
SELECT @@GLOBAL.TRANSACTION_ISOLATION;
+--------------------------------+
| @@GLOBAL.TRANSACTION_ISOLATION |
+--------------------------------+
| READ-COMMITTED |
+--------------------------------+这样,再有新的事务连接进来时,它们就只能查询到已经提交过的事务数据了。但是对于当前事务来说,它们看到的还是未提交的数据,例如:
-- 正在操作数据事务(当前事务)
START TRANSACTION;
UPDATE user SET money = money - 800 WHERE name = '小明';
UPDATE user SET money = money + 800 WHERE name = '淘宝店';
-- 虽然隔离级别被设置为了 READ COMMITTED,但在当前事务中,
-- 它看到的仍然是数据表中临时改变数据,而不是真正提交过的数据。
SELECT * FROM user;
+----+-----------+-------+
| id | name | money |
+----+-----------+-------+
| 1 | a | 900 |
| 2 | b | 1100 |
| 3 | 小明 | 200 |
| 4 | 淘宝店 | 1800 |
+----+-----------+-------+
-- 假设此时在远程开启了一个新事务,连接到数据库。
$ mysql -u root -p12345612
-- 此时远程连接查询到的数据只能是已经提交过的
SELECT * FROM user;
+----+-----------+-------+
| id | name | money |
+----+-----------+-------+
| 1 | a | 900 |
| 2 | b | 1100 |
| 3 | 小明 | 1000 |
| 4 | 淘宝店 | 1000 |
+----+-----------+-------+但是这样还有问题,那就是假设一个事务在操作数据时,其他事务干扰了这个事务的数据。例如:
-- 小张在查询数据的时候发现:
SELECT * FROM user;
+----+-----------+-------+
| id | name | money |
+----+-----------+-------+
| 1 | a | 900 |
| 2 | b | 1100 |
| 3 | 小明 | 200 |
| 4 | 淘宝店 | 1800 |
+----+-----------+-------+
-- 在小张求表的 money 平均值之前,小王做了一个操作:
START TRANSACTION;
INSERT INTO user VALUES (5, 'c', 100);
COMMIT;
-- 此时表的真实数据是:
SELECT * FROM user;
+----+-----------+-------+
| id | name | money |
+----+-----------+-------+
| 1 | a | 900 |
| 2 | b | 1100 |
| 3 | 小明 | 1000 |
| 4 | 淘宝店 | 1000 |
| 5 | c | 100 |
+----+-----------+-------+
-- 这时小张再求平均值的时候,就会出现计算不相符合的情况:
SELECT AVG(money) FROM user;
+------------+
| AVG(money) |
+------------+
| 820.0000 |
+------------+虽然 READ COMMITTED 让我们只能读取到其他事务已经提交的数据,但还是会出现问题,就是在读取同一个表的数据时,可能会发生前后不一致的情况。这被称为不可重复读现象 ( READ COMMITTED ) 。
7.4.3 幻读
将隔离级别设置为 REPEATABLE READ ( 可被重复读取 ) :
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SELECT @@GLOBAL.TRANSACTION_ISOLATION;
+--------------------------------+
| @@GLOBAL.TRANSACTION_ISOLATION |
+--------------------------------+
| REPEATABLE-READ |
+--------------------------------+测试 REPEATABLE READ ,假设在两个不同的连接上分别执行 START TRANSACTION :
-- 小张 - 成都
START TRANSACTION;
INSERT INTO user VALUES (6, 'd', 1000);
-- 小王 - 北京
START TRANSACTION;
-- 小张 - 成都
COMMIT;当前事务开启后,没提交之前,查询不到,提交后可以被查询到。但是,在提交之前其他事务被开启了,那么在这条事务线上,就不会查询到当前有操作事务的连接。相当于开辟出一条单独的线程。
无论小张是否执行过 COMMIT ,在小王这边,都不会查询到小张的事务记录,而是只会查询到自己所处事务的记录:
SELECT * FROM user;
+----+-----------+-------+
| id | name | money |
+----+-----------+-------+
| 1 | a | 900 |
| 2 | b | 1100 |
| 3 | 小明 | 1000 |
| 4 | 淘宝店 | 1000 |
| 5 | c | 100 |
+----+-----------+-------+这是因为小王在此之前开启了一个新的事务 ( START TRANSACTION ) ,那么在他的这条新事务的线上,跟其他事务是没有联系的,也就是说,此时如果其他事务正在操作数据,它是不知道的。
然而事实是,在真实的数据表中,小张已经插入了一条数据。但是小王此时并不知道,也插入了同一条数据,会发生什么呢?
INSERT INTO user VALUES (6, 'd', 1000);
-- ERROR 1062 (23000): Duplicate entry '6' for key 'PRIMARY'报错了,操作被告知已存在主键为 6 的字段。这种现象也被称为幻读,一个事务提交的数据,不能被其他事务读取到。
7.4.4 串行化
顾名思义,就是所有事务的写入操作全都是串行化的。什么意思?把隔离级别修改成 SERIALIZABLE :
SET GLOBAL TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SELECT @@GLOBAL.TRANSACTION_ISOLATION;
+--------------------------------+
| @@GLOBAL.TRANSACTION_ISOLATION |
+--------------------------------+
| SERIALIZABLE |
+--------------------------------+还是拿小张和小王来举例:
-- 小张 - 成都
START TRANSACTION;
-- 小王 - 北京
START TRANSACTION;
-- 开启事务之前先查询表,准备操作数据。
SELECT * FROM user;
+----+-----------+-------+
| id | name | money |
+----+-----------+-------+
| 1 | a | 900 |
| 2 | b | 1100 |
| 3 | 小明 | 1000 |
| 4 | 淘宝店 | 1000 |
| 5 | c | 100 |
| 6 | d | 1000 |
+----+-----------+-------+
-- 发现没有 7 号王小花,于是插入一条数据:
INSERT INTO user VALUES (7, '王小花', 1000);此时会发生什么呢?由于现在的隔离级别是 SERIALIZABLE ( 串行化 ) ,串行化的意思就是:假设把所有的事务都放在一个串行的队列中,那么所有的事务都会按照固定顺序执行,执行完一个事务后再继续执行下一个事务的写入操作 ( 这意味着队列中同时只能执行一个事务的写入操作 ) 。
根据这个解释,小王在插入数据时,会出现等待状态,直到小张执行 COMMIT 结束它所处的事务,或者出现等待超时。